论文阅读_语音合成综述
基本信息
题目:Survey on Neural Speech Syntheis
论文地址:https://arxiv.org/abs/2106.15561
上传时间:2021 年 1 月
全文翻译:论文学习:A Survey on Neural Speech Synthesis
阅读体会
比较全面介绍用深度学习实现语音合成的综述性论文。论文整体 63 页,其中正文 37 页,参考 TTS 相关论文 400 多篇。本文并不打算对论文逐句翻译,只列出重点,作为个人阅读笔记,同时加入笔者的一些注释。
摘要
近年来基于神经网络的深度学习算法大大提升了语音合成的质量,这篇文章集学术研究和工业应用于一体,是一篇综述性的文档,它包含语音合成的几个重要组成部分:文本分析、声学模型和声码器;涉及热门主题,比如:快速 TTS,使用更少资源训练等等;还总结了 TTS 相关资料(工具和数据),最后讨论了 TTS 未来的发展方向。
1. 介绍
TTS 主要指的是把文本转换成语音输出,它是一个由来已久的课题,涉及:语言学、声学、数据信号处理、机器学习等领域。这几年深度学习使 TTS 效果有了显著提升,这篇论文是对深度学习 TTS 的综述。
1.1 TTS 历史
(从 12 世纪开始……此处省略)早期的计算机语音合成包括:频谱参数合成、音素合成、连接合成等方法;之后基于统计的机器学习算法,来预测频谱、基频、长度等合成参数;从2010 年之后,基于神经网络的语音合成占据主导地位,实现了更好的合成效果。
频谱参数合成
算法模拟嘴唇、舌头、声门和声道的动作产生语音。理论上,它模拟了人类发音方法,是最有效的合成法,而实际上很难采集各个参数的数据,因此该方法效果往往比后面几种方法效果差(笔者注:发音像“机器人”一样的“金属音”)。共振峰合成
基于一系列规则控制录波器模型产生语音,规则用于模拟共振峰及其谐波的特征,它由合成模型和声学模型组成,通过一系列参数控制,如基频、音色、噪音等。它合成出的音质较高,占用资源较低,使用于嵌入式系统,且不依赖大量的语料库,但相对来说合成效果不够自然,这是由于很难针对自然度描述规则。基于连接的合成
基于连接的方法依赖存储在数据中大量的语音片断,它包括从整句到音节的播音员录音,在合成过程中,算法搜索最值语音片断,通过连接这些片断产生合成语音,它产生的语音具有较高的读性,更接近播音员的音色,但需要录制大时音频,且在情绪、自然度、韵律、流畅度方面较差。基于统计的合成
基于统计的合成简称 SPSS(statistical parametric speech synthesis),与基于连接合成不同的是,它生成声数参数,然后通过利过算法利用这些参数复原语音,它通常由文本分析、声学模型(参数预测)、声码器三部分组成,如图 1 所示(三部分后面详述)。该类模型的优点是:合成效果更自然、灵活性更高(可调节参数);较低的资源占用。它的缺点的:合成的声音可能带有噪音,听起来有些像机器人,而非自然的人声。

- 基于神经网络的合成
随着神经网络技术发展,神经网络被引入了 SPSS,作为其中的声学模型替代 HMM 统计模型预测参数,后来又发展出了直接用音素生成音频的模型,WaveNet 被视为首例神经网络 TTS 模型,后来又发现出了 end-to-end 模型,将文字直接转换成音频。相对于之前的模型,它在自然度和智能性都有更高水平,并且更少依赖人工预处理和特征工程。
1.2 文章组织方式

论文主要包含两大主题:TTS 的主要组成、TTS 高级主题。
- 第一部分简单介绍
- 第二部分介绍了 TTS 主组由上图的三部分组成:文本分析(Text Analysis)模块将文本序列转换为语言特征,声学模型(Acoustic Model)从语言特征生成声学特征,声码器(Vocoder)从声学特征合成波形。及其模型的实现。
- 第三部分介绍一些前沿问题,如:提升模型速度,减少资源占用,用少量数据更训练效果更好的模型,提升鲁邦性解决丢音、重复等问题,加强情感表达,通过不量训练模拟某人语音等。
- 第四部分列出了开源的代码和语料库资源。
- 第五部分总结展望。
2. 主要组成部分
主要介绍上图中三部分的神经网络实现,
2.1 主要分类
一般将语言合成分成文本分析、声学模型、声码器三部分,以及 end-to-end 模型。文本分析把文本转换成语言学特征,声学模型把语言学特征转换成声学特征,声码器将声学特征转换成音频。而 end-to-end 模型直接将文本转换成音频。也可将其中的几个步骤放在一个模型中,如图 所示:
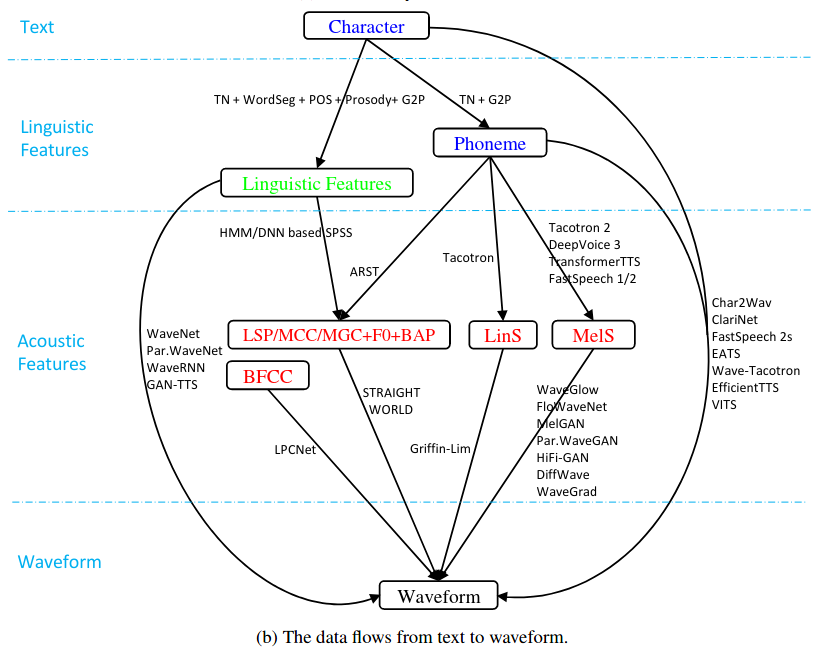
2.2 文本分析
文本分析将文本转换成包含语音和韵律的特征。在统计参数合成中,文本分析用于提取语言特征向量序列,并且包含诸如文本规范、短语切分、标注成份,韵律预测,字符到音素转换等功能。尽管 end-to-end 模型,大幅简化了文本分析功能,但一般情况下还是需要做一些规范化和字符到音素映射的工具。文本分析一般包含以下步骤:
- 文本规范化:将 "1989", "Jan 24" 转换成对应文本,规范化一般基于规则;也有一些神经网络模型利用序列处理解决这一问题;之前有人研究结合规则和神经网络来提升效果。
- 短语切分:像中文需要将字分成词再进行下一步处理。
- 标注成分:标句子成份,如:名词、动词……
- 韵律预测:韵律包含节奏、重音和语调,它们与时长、音量和音高相对应,这些因素在言语交际中起着重要作用,对于不同语言也有不同处理,对于中文,韵律词、韵律短语和语调短语构成了韵律树三层结构,利用 RNN, CRF, Self-Attention 等方法来解决该问题。
- 字符到音素转换:将字符转换成音标(拼音),主要通过查表方法实现,对于英文这种字母单音,字典不能涵盖所有单词,因此需要模型或规则辅助转换,对于中文,除字典以外,也需要根据上下文处理多音字,这也需要用模型消歧。
综上,文本分析需要从音素、音节、词、短语和句子等不同层面来构建语言特征。文本分析与神经网络有很多结合,比如用一个神经网络实现文本分析的任务。韵律对语音的自然度有很大影响,在神经网络模型简化模型的基础上,也将音高、时长、断句、呼吸、停顿等因素加入了编码器的上层。另外,还有一些方法来支持韵律特征:(1) 从语音中学习韵律规则; (2) 利用无监督数据学习韵律生成预测训练模型 (3) 使用图网络来结合语法信息。
2.3 声学模型
声学模型将语言学特征转换成声学特征,具体实包括在 SPSS 中使用 HMM 或 DNN 实现的静态参数模型;基于 encoder-attention-decoder 框架的序列模型;以及最新的用于并行生成器的前馈网络。可以将声学模型分为两种:SPSS 中的声学模型,根据语言特征预测 MGC、BAP 和 F0 等声学特征;以及基于神经的 end-to-end 模型,其根据音素或字符来预测声学特征。
2.3.1 SPSS 中的声学模型
这类模型的研发由以下几个因素驱动:1) 可采用更多的上下文信息作为输入;2) 可以考虑到输出帧之间的相关性;3) 处理语言特征到声学特征的映射是一对多的情况。
HMM 隐马尔模型可用于生成语音参数,与之前的拼接方法相对,HMM 在改变说话人、情感、风格等方面比较灵活,它的主要缺点是音质较少,原因是:1) 声学模型精度不高,过于平滑缺乏细节;2) HMM 模型能力的不足使声音编码技术受限。
DNN 深度神经网络模型提升的合成的质量;LSTM 类模型又考虑了远距离上下文的影响;后续还有使用 CBHG,GAN,基于 Attention 的循环神经网络来进一步改善声学模型的品质。
2.3.2 End-to-end 的声数模型
end-to-end 的声学模型对于传统的 SPSS 模型,有以下有事:1) 不需要对齐语言特征和声学特征,简化了预处理;2) 为了提高性能,输入的语言特征被简化为字符或音素序列,输出声学特征从低维的 MGC 向高维的 Mel 谱图甚至更高维线性谱图转变。
基于 RNN 的模型(Tracotron 系列)
Tacotron 利用注意力框架,输入作为字符线性谱输出,并使用 Griffin-Lim 算法来生成波形。Tacotron2 使用附加的 WaveNet 模型来生成梅尔谱图并生成波形。Tacotron 2 比以往的拼接 TTS、参数 TTS、神经 TTS 的语音质量有了很大的提高。
后来有很多工作从不同方面对 Tacotron 进行了改进:1) 采用参考编码器和风格符号来增强语音合成的表现力,2) 去掉注意机制,用时间长预测实现自回归,3) 将自回归生成改为非自回归,4) 建立端到端的文本生成波形模型。
基于 CNN 的模型(DeepVoice 系列)
DeepVoice 用卷积神经网络优化了 SPSS 系统。通过神经网络获取语言特征后,基于 WaveNet 的声码器生成波形。DeepVoice 2 通过改进的网络结构和支持多说话人来增强 DeepVoice。它还采用了 Tacotron+WaveNet 的 pipeline,首用 Taco tron 生成线谱图,然后使用 WaveNet 生成波形。DeepVoice 3 利用全卷积网络结构进行语音合成,它可以从字符生成梅尔谱图,并可扩展到多说话人数据集。并使用了更紧凑的序列到序列模型,跳过了生成语言特征的步骤。
之后,ParanNet 是完全基于卷积的非自回归模型,可以加快梅尔谱图的生成速度,并获得较好的语音质量。DCTTS 与 Tacotron 共享类似的 pipeline,并利用基于完全卷积的 attention 网络从字符序列生成梅尔谱图。它们使用超分辨率网络获得线性谱图,并使用 Griffin-Lim 合成波形。
基于 Transformer 的模型(FastSpeech 系列)
TransformerTTS 利用 attention 框架从音素产生梅尔图谱。之前基于 RNN 的 attention 网络主要存在两个问题:1) 编码器和解码器不能并行训练,编码器不能并行预测,影响了使用效率;2) RNN 对于长序列的依赖关系建模效果较差。TransformerTTS 采用了 Transformer 的基本模型结构,并吸收了 Tacotron2 中解码器、前网/后网和预测停止符号的设计。它的音质与 Taco tron2 相当,但训练时间更短。Transformer 由于并行计算而并不很稳定,又出现了 MultiSpeech 通过编码器归一化、解码器瓶颈和对角注意约束等方式,提高了注意机制的健壮性,而 RobuTrans 利用持续时间预测来增强自回归的健壮性。
前面所述模型都使用自回归的生成器有以下问题:1) 预测速度慢,2) 健壮性问题:由于文本与梅尔谱图之间的对齐不准确造成的跳词、重复问题。FastSpeech 提取了以下解决办法:1) 用前馈的 Transformer 网络提升预测速度,2) 移除了注意力机制,以避免重复和跳词,以解决健壮性问题。解决方案是使用长度调节器来解决音素和梅尔语谱图序列之间的长度不匹配(具体方法在 3.4.2 节中介绍),便于并行生成。FastSpeech 的 音质与之前的自回归模型差不多。
FastSpeech2 主要从两个方面提升了 FastSpeech:1) 使用真实的梅尔谱图作为训练目标,以替代自回归教师模型中提取出的梅尔谱图作为训练目标。这简化了流程,也避免了蒸馏导致的信息丢失。2) 提供更多的信息,例如音调、时长和能量作为解码器输入,这简化了文本到语音的一对多映射问题。FastSpeech 2 获得了更好的音质,并保持了 FastSpeech 快速、健壮且可控的语音合成优势。FastPitch 通过使用音调信息作为解码器输入来改进 FastSpeech。
其它声学模型
除了上述模型,还有一些基于 Flow, GAN, VAE, Diffusion 的声学模型,具体见下表(最下面)
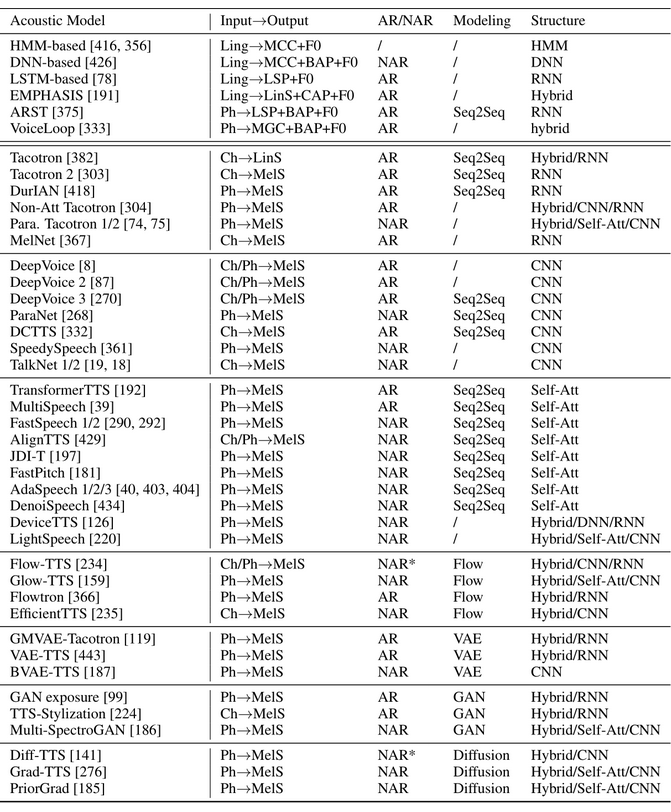
2.4 声码器
声码器可分为两类,一类用于组成 SPSS;一类是基于神经网络的声码器。第一类一般包含两部分:声码分析和声码合成,声码分析从声音中提取梅尔倒谱、非周期频谱和基频等声学特征,合成阶段将声学特征合成为音频。
早期的神经网络直接把语言特征作为输入产生音频,后来把梅尔倒谱作为输入。生成较长的音频时,自回归需要很长时间计算,引入 Flow、GAN、VAE、DDPM 模型又改进了这些问题。
自回归声码器
自回归模型是统计上一种处理时间序列的方法,即使用 x1 至 xt-1 来预测 xt,并假设它们为 x 在时序上呈线性关系,由于它使用 x 预测自已,所以叫自回归。
WaveNet 使用扩展卷积实现自回归来生成音频,与传统的分为分析和合成两步的 SPSS 不同,WaveNet 在声码器部分使用 End-to-end 模型,因为不需要额外的先验知识,WaveNet 的输入是语音学特征,输出是线性谱或梅尔图谱。它虽达到了较好的音质,但用时较长。后续模型对此进行了改进,如 SampleRNN 使用多层 RNN 网络实现无条件生成音频,进而 Char2Wav 实现在声学特征的基本上有条件生成音频。WaveRNN 使用 RNN、双 Softmax 层、权重修剪和缩放等技术减少了计算量。LPC-NET 将传统的数字信号处理引入神经网络,使用线性预测系数计算下一个波形点,以及用轻量级 RNN 计算残差。LPCNet 根据 BFCC 特征产生语音波形……
基于流的声码器
基于流的模型是一种生成模型。生成模型是给定训练数据,要生成与该数据分布相同的新样本,即用一个概率模型来拟合给定的训练样本。基于流的神经网络分为以下两种类型:
自回归变换
如逆自回归流 IAF 可以看作是自回归流 (AF) 的对偶公式。AF 的训练是平行的,而生成采样是顺序的。相反,IAF 中的生成采样是并行的,而似然估计的推理是顺序的。并行 WaveNet 利用概率密度蒸馏将 IAF 的有效采样与 AR 建模的有效训练结合起来,但它依赖于复杂的师生训练,并且计算量大。
二部变换
保证变换是可逆的,二部变换利用仿射耦合层,确保可以从输入可以计算输出,输出也能计算输入。它可达到高音质和更快的速度。
上述两种变换各有优缺点
自回归变换对数据分布 x 和标准概率分布 z 之间的相关性建模,因而具有更好的表现力,但相对复杂;二部变换相对简单,但需要大量参数;综合二项,WaveFlow 提供了基于似然的模型的统一视图来实现并行预测。
基于 GAN 的声码器
生成对抗网络 GAN 常用作生成器,如生成文本、生成声音、生成图片等,它一般包括生成器和鉴别器两部分。一般名字里带 GAN 的 TTS 都使用了生成对对抗网络。
生成器
大多数 GAN 的声码器使用扩展卷积来增加接受场来模拟波形序列中的长相关性,并用上采样条件信息匹配波形序列的长度。如:选择对条件信息进行一次上采样,然后进行膨胀卷积以保证模型容量。上采样过早地增加了序列长度,导致较大的计算量。因此,一些编码器选择迭代上采样并进行扩展卷积,以避免较低层的过长序列。vocGan 提出了一种多尺度生成器,输出不同尺度的波形序列。HiFi-GaN 通过多感受场融合模块并行处理不同长度的不同图案,在合成效率和样品质量之间进行折衷。
鉴别器
鉴别器。鉴别器的目的是捕捉波形特征,从而引导生成器更好地生成音频。1) 随机窗口鉴别器(InGaN-TTS)使用多个鉴别器来鉴别波形的不同随机窗口,它以不同的互补方式评估音频,简化全音频的真假判断;2) 多尺度鉴别器(Melgan)使用多个鉴别器来判断不同尺度 (音频下采样) 的音频,每个尺度上的鉴别器可以聚焦于不同频段的特征;3) 多周期鉴别器(HiFi-GaN)利用多个鉴别器鉴别等间距样本,通过观察输入信号在不同周期的不同部分,捕捉到不同的隐含结构。4) 分级鉴别器(vocGAN)对产生的波形从粗粒度到细粒度进行不同分辨率的判别,引导生成器学习低频和高频声学特征与波形的映射关系。
损失函数
新模型也对损失函数对行了改进,用于提高对抗训练的稳定性和效率,并改善感知音频质量。
基于扩散的声码器
DDPM 去噪扩散概率模型的基本思想是用扩散过程和逆过程来表征数据与潜在分布之间的映射关系:在扩散过程中,波形数据样本逐渐加入一些随机噪声,最后变成高斯噪声;在反向过程中,随机高斯噪声逐步去噪为波形数据样本。基于扩散的声码器可以产生非常高音质的语音,但迭代过程时间长,推理速度慢。很多模型都致力于解决这一问题。
其它声码器
还有其它一些工作,如:在保持语音生成可控的同时实现高语音质量。通过综合实验对几种常见声码器进行评估,研究声码器的鲁棒性等。
讨论
总结如下:
- 基于自回归 (AR) 相比于其它模型在数学上更简单。
- 除 AR 之外,所有的生成模型都可以支持并行语音生成。
- 除 AR 之外,所有的生成模型都能在一定程度上支持潜在的调控。
- 基于 GAN 的模型不能估计数据样本的似然。
2.5 走向完全的 End-to-end 模型
End-to-end 端到端的模型输入是字符或音素,输出是音频,它的优点是:需要较人的人工标注和特征提取;2) 避免了流式模型向后传递错误的问题;3) 减小了训练,开发和部署的成本。
它面临的最大挑战是由于模态不同,输入字符和输出音频之间长度无法匹配。比如 20 个单词,对应 100 个音素,生成 80k 长度的音频序列,由于内存限制,难于全部训练,切块训练又难以取得上下文的表征。
为解决这一问题,神经网络 TTS 发展经历了一个从 SPSS 走向 End-to-end 的渐进发展过程,如下图 所示。1) 简化文本分析模块和语言功能,只保留文本归一化和字音素转换,将字符转换成音素,或者直接将字符作为输入去掉整个文本分析模块。2) 简化声学特征,将复杂的声学特征简化为 Mel 谱图。3) 将两个或三个模块替换为单个端到端模型。
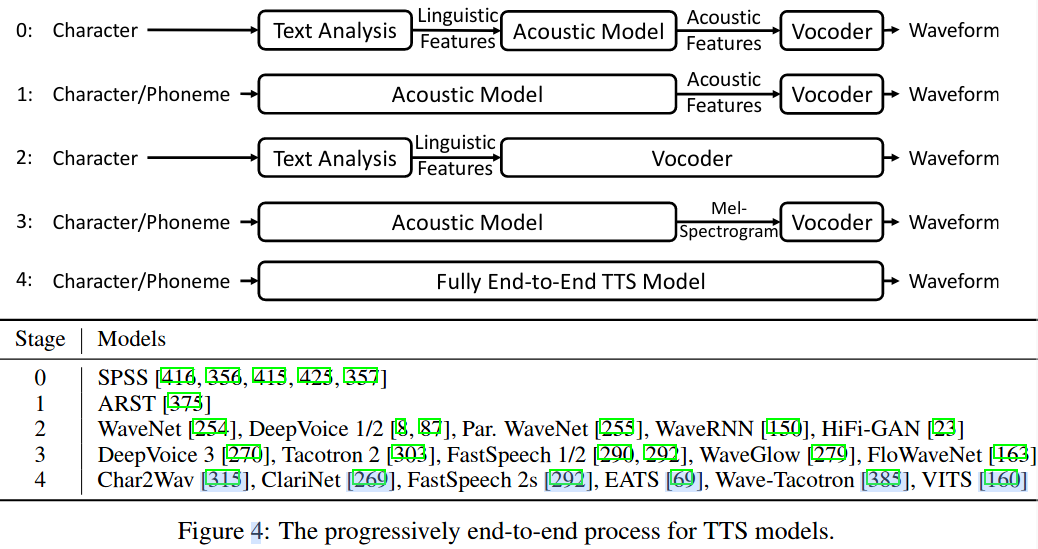
- 场景 0:最基本的 SPSS 模型结构,使用了三个基本模块。
- 场景 1:将文本分析和声学模型合并成一个端到端的模型,从音素生成声学模型生,转给声码器产生音频。
- 场景 2:WaveNet 第一次从语言学特征直接生成音频输出,可将它看作合并了声学模型和声码器,但它仍需要文本分析模型来生成语言学特征。
- 场景 3:Tacotron 提出了简化语言特征和声学特征的方案,使用编码器 - 注意力模型 - 解码器模型直接从字符/音素预测线性谱图或梅尔图谱。
- 场景 4:输入为字符或音素,输出为音频的端到端模型。Char2Wav 从字符生成声学特征,SampleRNN 生成波形,结合这两个模型可用于直接语音合成。类似地,ClariNet 联合直接产生波形的自回归声学模型和非自回归声码器;FastSpeech 2s 直接使用并行结构的文本生成语音,可以极大地提高预测速度;EATS 的并行模型直接从字符/音素生成波形,它利用持续时间内插和软动态时间回绕损耗进行端到端对齐学习。Wave-Taco tron 在 Taco tron 上构建了一个基于流的解码器,直接产生波形。
2.6 其它分类方法
除了以上的分类方法,还可以把模型分为:1) 自回归模型和非自回归模型;2) 根据生成模型的方式,可分为: 普通生成模型,流模型,GAN,VAE 以及 diffusion 传播模型;3) 按网络结构可分为 CNN,RNN,自注意力模型和混合模型。
3 TTS 高级主题
3.1 背景和分类
本章的内容主要讨论一些前沿研究和应用。3.2 部分将讨论对自回归模型的加速以及缩减模型大小;3.3 讨论如何提升合成效果的自然度和易懂,例如:在训练数据较少的情况下,如何有效地训练模型;3.4 讨论加强模型的鲁棒性,如改进丢词重复等问题,以提升模型的易懂性。3.5 讨论如何通过控制模型的风格和韵律以提升模型的表现力;3.6 讨论使用少量数据训练,适配参数,来训练转换目标说话人,以实现高质量的语音适配的应用。
3.2 TTS 加速
TTS 服务经常部署在云端或者在嵌入式系统中支行,需要较快的合成速度。早期的模型对于长文本合成速度较慢,为解决这一问题,出现的技术方案包含:1) 使用非自回归模型产生梅尔图谱以及并行化生成音频;2) 轻量和有效的模型结构;3) 利用领域知识加快语音合成,具体方法如下:
并行生成器
各个模型的时间复杂度如下表所示

模型减重
非自回归模型虽然加快了训练和预测的速度,但并没有简化模型参数和训练量,对于嵌入设备模型减重也非常重要,与此相关的工作主要集中在:修剪、量化、知识提炼和神经结构搜索。
使用领域知识加速
加入领域知识可加速预测,具体方法如:
线性预测:将数字信号处理与神经网络相结合,采用线性预测系数计算下一个波形,采用轻量级模型预测残差值,加快了自回归波形生成的推理速度。
多频带/子频带建模:把音频拆成多个子频带,用于加快声码器的速度。
除此以外,还有利用充分聚束和比特聚束减少计算复杂度;流合成即不等待全句只对现在 token 合成加快预测速度;用简单结构模拟快速傅里叶变换;用帧分割和交叉递减,并行合成波形的某些部分,然后将合成的波形串联在一起,以确保低端设备上的快速合成等方法。
3.3 使用少量资源训练模型
一般情况下,训练模型都需要大量高品质的文本和音频数据,但世界上的很多语言没有足量数据,所以商业软件一般只支持十几种常用语言。对于小语种合成商业产值不大,但很有社会意义。为实现这一目标,产生了以下技术。
自监督训练
文本和音频对很难收集,但收集未配对的相对容易。自监督训练被用于提升语音的可懂度和语音的生成能力。比如使用预训练的 BERT 模型作为编码器,使用预训练的自回归梅尔图谱生成器作为解码器,建立语音转换任务联合训练,此外,可以将语音量化为离散的 token 序列,以与音素或字符序列相似。以此方式预训练 TTS 模型,然后在少数真正配对的文本和语音数据上微调该 TTS 模型。
跨语言转换
由于人类的语音使用类似的发声器官,读音和语义结构,丰富的语言训练出的模型,可以映射到小语种模型中。由于音素略有差异,所以需要对 Embedding 层进行一些处理;采用国际音标 (IPA) 或字节表示法可以支持多语言的任意文本。此外,在进行跨语言迁移时也可以考虑到了语言的相似性。
转换发音者
当某个说话人的语音数据有限时,可以利用来自其他说话人的数据来提高该说话人的合成质量。具本方法是通过语音转换将其他说话者的语音转换为该目标语音以增加训练数据,或者通过语音适配或语音克隆使针对其他语音训练的 TTS 模型适应该目标语音,此问题将在在 3.6 节进一步讨论。
语音链反向转换
语音合成和语音识别是对偶的两组应用,可以利用它们之前的关系互相改善。
利用低品质数据
在网络上存在一些低质量的文本音频对,从中可以挖掘并改进 TTS 模型质量,比如利用它们来降噪、去纠缠等。
3.4 TTS 鲁棒性
影响 TTS 鲁棒性的通常是声学模型中经常会出现跳词、重复、注意力崩溃等等问题。有以下两个原因:
- 难以对齐梅尔图图谱和字符音素。有两种解决方法,一种是改善注意力模型;另一种是使用时长预测代替注意力模型。
- 自回归生成中的偏差爆炸和误差传播。有两种解决方法,一种是改进自回归模型,另一种是用非自回归取代自回归模型。
声码器不会面临上述问题,因为声学特征和波形已经按帧对齐。
3.4.1 提升注意力机制
自回归的声码器的问题常常是由于编码器 - 注意力 - 解码器结构中注意力对齐(文本和音频特征对齐)问题引起的,下面是核心问题:
- Local:一个字符可对应多个音频帧,而每帧只对应一个字符;可用于解决注意力崩溃问题问题。
- Monotonic(单调性):字符有先后顺序,如果字符 A 在 B 前,则输出音频 A 也在 B 前,可用于解决重复问题。
- Complete(完备性):每个字符至少对应一帧,可用于解决丢音问题。
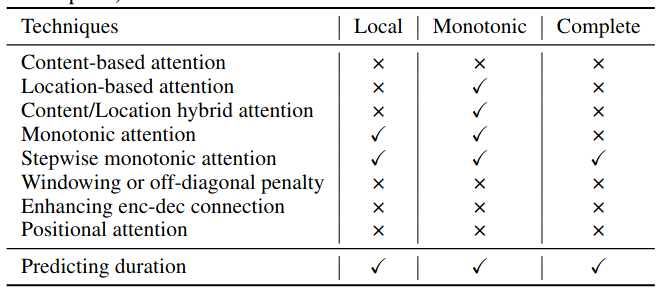
具体方案如下:
Content-based attention(基于内容的注意力)
早期的注意模型是基于内容的,注意力的分布取决于编码器和解码器之间隐藏层的匹配度。Attention 模型一开始用于解决翻译等问题,翻译中源和目标中的词可按含义来对义,但对于语音合成和语音识别问题的对齐则比较困难,需要注意上述的三个核心问题。
Location-based attention(基于位置的注意力)
根据位置对齐文本和音频特征,使用它可以保证单调性。
Content/Location-based hybrid attention(基于内容和位置的混合注意力)
结合了上下文和位置对齐两种方法,使用前一个注意力对齐来计算当前注意力对齐,也用于解决单调性问题。
Monotonic attention(单高性注意力)
在对齐时参考了位置单调增加的原理,从而解决了丢音和重复的问题,为保证完备性,He et al.又提出了步进单调注意力,保证对齐注意力位置每次只前进一步,从而保证不跳过任何一个单元。
Windowing or off-diagonal penalty(加窗和非对角线处罚)
由于单调可知,输入和输出呈对角线关系,因此,提取了将注意力限定在子窗口中,从而降低了学习灵活性和难度;另外,通过构造掩码,使用损失函数惩罚的方式,鼓励注意力分布在对角线附近区域内(band),
Enhancing encoder-decoder connection(提升编解码器的连接)
输出帧之间有很强的相关性,解码器常常更多的考虑前其之前帧的数据,从而忽略了编码器的输入。因此很多工作在编解码器之间建立更强的链接,从而改进注意力的对齐能力。比如:在每个时间步产生多帧预测;丢弃之前的信息,以减少对后面预测的影响;提高编解码之间位置的关联性;鼓励输出的梅尔图谱包含更多文本信息。
Positional attention(位置注意力)
有一些非自回归模型,使用位置作为 query,加入 key,value 的计算(详见 attention 模型)。
3.4.2 用长度预测取代注意力
上述的注意力模型改进无法解决所有问题,一些人试图用预测各字符输出音频的长度来解决问题,以替代注意力模型,这有点像之前 SPSS 中的长度预测。一般有两种做法:第一种是使用扩展工具联合训练,给长度打标签;第二种是使用真实时长代入训练 End-to-end 模型,在预测时预测出长度。
外部对齐
引用外部工具实现对齐,主要包括以下几种:1) 从编解码注意力模型中获取持续时间标签;2) 基于语音识别的 CTC 对齐音素和梅尔图谱输出;3) 隐马尔可夫对齐基于蒙特利尔强制对齐提取时间长度。
内部对齐
Align 使用动态规划法通过多阶段训练学习文本和梅尔图谱之前的关系;JDI-T 借鉴 FastSpeech 从自回归教师模型中提取时长,但不需要两阶段训练;Glow-TTS 单调对齐搜索来提取持续时间;EATS 利用插值和 DTW 优化端到端时间预测。
对 End-to-end 优化
典型的时间预测方法用内部或外部的对齐工具提取时间用于训练;用预测的时长用于整个模型的预测。利用梅尔图谱的损失函数来优化模型。
End-to-end 优化
EATS 使用内部模块预测时长,并借助时长插值和软 DTW 损失对时长进行端到端的优化。非注意模型 Tacotron 提出了半监督学习方法,如果没有持续时间标签可用,则预测的时长可以用于上采样。
3.4.3 提升自回归模型效果
自回归模型常常遇到偏差爆炸误差传播问题,偏差爆炸是由于在训练过程中,使用上一步的输出作为下一步的输入,而预测时上一步的输出也是预测出来的。训练和预测的差异导致错误在预测时错误不断向后传播,偏差在短时间内很快积累起来。
目前研究了不同的方法来缓解上述问题。Guo 等利用教授强迫来缓解实际数据和预测数据的不同分布的差异。刘等进行师生蒸馏方法,教师接受教师强迫模式的训练,学生之先前预测的值作为输入,优化以减小教师和学生模型之间隐藏状态的距离。生成的梅尔谱图序列的右侧通常比左侧差,因此利用从左到右和从右到左的生成来进行数据扩充和规范化;Vainer and Dušek 提出了数据扩充的方法,将高斯噪声加入图谱来模拟预测误差,并通过随机替换几个帧来降低输入谱的质量,以鼓励模型依赖使用更远的帧生成。
3.4.4 用非自回归替换自回归
非自回归模型可划分为两类:ParaNet 和 Flow-TTS 使用上文中提到的位置注意力(positional attention)对齐文本的语音; FastSpeech 和 EATS [69] 使用时长预测解决文本和语音序列之间错位的问题。AR 和 Attention 有以下组合:

3.5 TTS 表现力
语音的自然度很大程度上依赖表现力,与此相关的研究包括:内容、音色、韵律、风格、情感等方面的建模、解缠、控制和传递等。
语音表现力中一个关键问题是一对多映射,单一文本对应多个语音参数,如时长,音高,音量,风格,情感等。如果只使用 L1 损失函数且没有丰富的输入信息,将导致过于平滑的梅尔图谱预测,比如只对数据库里的单音素建模,将导致低音质和低表现力。因此,需要提供更多样的信息做为建模的输入。另外,使用更多多信息作为输入后,可实现:1) 通过控制参数控制合成效果;2) 转换语音风格;3) 为实现细力度的控制,需要分解内容、韵律、音色和噪音等各个因素。
3.5.1 参数信息分类
文本信息
需要表达的内容,如文本或者音素,一些方法可以通过词嵌入或文本预训练的方式来提高合成质量和表现力。
发音人音色
发音人相关特征,支持多发声者的 TTS 系统需要对声音人的特征建模。
韵律、风格和情感
韵律、风格和情感是提升表现力的主要方法,包含了包含语调、重音和节奏以及如何说出文本。
录音设备和环境噪声
设备和环境是语音的通道,它与上述三点不相关,但也影响了音质,这方面的研究围绕合成中的分解,控制,降噪。
3.5.2 参数信息建模
与表现力相关的参数包括:
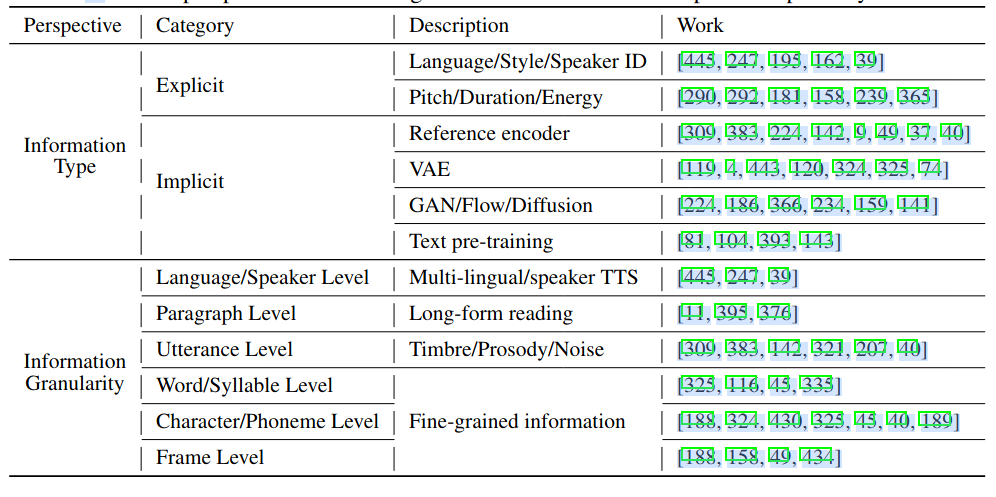
信息类型
信息类型可分为外显和内隐两种,外显型可以明确打标签;内隐型只能通过计算获取其参数。
对于外显型,我们可以直接使用它作为模型输入,获取它的渠道包含:1) 获取语言 ID,声音者 ID,韵律的标签数据,比如韵律数据的标注方法如 ToBI,AutoBI,Tilt,SLAM 等;2) 从音频中提取音高、能量,时长等。
除了外显型数据还包含一些更细粒度的参数,可通过模型从数据中提取,典型的建模方法包括:
参考编码
Kerry-Ryan 等人将韵律定义为去除由于文本内容后语音信号中剩余的变化,音色、通道效果和模型韵律不需要编码器来标注。它从参考音频中提取韵律,作为解码器的输入。在训练过程中,使用真实参考音频,在推理过程中,使用另一参考音频来合成具有相似韵律的语音。Wang 从参考音频中提取嵌入内容,并将其用作查询来参与 (通过基于 Q/K/V 的注意力) 风格标记库,并且将关注结果用作用于模型的韵律条件。从而增加 TTS 模型学习不同类型样式的能力和变化性,使数据集中不同数据样本之间的知识共享成为可能。风格符号库中的每个符号可以学习不同的韵律表征,例如不同的语速和情绪。在推理过程中,利用参照音和提取的韵律,简单地选择风格符号来合成语音。
变量自动编码
张等人利用 VAE 对潜在空间中的更多信息进行建模,利用高斯先验作为正则化,实现对合成风格的表现力建模和控制。一些研究还利用 VAE 框架更好地对表达合成的更多信息进行建模。
对抗生成模型
利用生成对抗模型对隐变量建模,学习更多信息,可优化一对多的映射问题,对抗预测过于平滑的问题,能够更好地模拟多模态分布。
文本预训练
使用预测训练的模型利用词嵌入和参数提升模型的表现力。
信息粒度
从粗到细分成六个粒度等级:1) 语音和发音者等级;2) 段落等级(由短语和句子构成);3) 短语等级,提取单个隐藏向量来表示该发音的音质/风格/韵律;4) 词/音节等别,它针对发音级别,但无法覆盖的细粒度风格/韵律信息;5) 字符/音素等级,包含持续时间、音高或韵律信息;6) 帧等级。
此外,还有使用多个不同粒度的层次结构建模,以提升表现力。Suni 等人论证了韵律层次结构在口语中的内在存在。Kenter 等人从框架和音素级别到音节级别预测韵律特征,并与单词和句子级别的特征串联。Hono 等人利用多粒度的 VAE 来获得不同的时间分辨率潜变量,并从较粗级别的潜变量采样较细级别的潜在变量。Sun 等人使用 VAE 对音素和单词级别的差异信息进行建模,并将它们组合在一起输入解码器。Chien 和 Lee 对韵律预测进行了研究,提出了从词到音级的层次结构来改进韵律预测。
3.5.3 分解、控制和转换
使用对抗训练分解
当风格和韵律信息纠缠在一起时,需要通过训练将它们分离,以加强合成模型的表现力,以及控制这些参数。Ma 等人利用对抗性、协作的方法,增强内容的解缠能力和可控性。Hu 等人通过对抗训练利用 VAE 框架,将噪音从说话人信息中分离出来。钱等人使用三个瓶颈重构来解开节奏、音高、内容和音色。Zhang 等人提出通过帧级噪声建模和对抗性训练来分离说话人的噪声。
使用循环一致性/反馈损失来控制风格
当提供风格标签等信息作为输入时,TTS 模型可合成具有相应风格的语音。为了增强 TTS 模型的可控性,一些工作提出使用周期一致性或反馈损失来鼓励合成语音在输入中包含差异信息。
- 利用半监督学习提升可控性
如果对音高、长度、能量、韵律、情感、发音人、噪音等属性都有标注,那到通过设置这些属性,很容易控制合成。但在没有这些标注,或只有部分标注的情况下,使用半监督学习方法,也可以实现分离这些特征。
- 通过控制差异信息实现变换
通过差异信息改变风格,如果有对差异的标注,对语音数据训练,从而根据标签在合成时转换风格。在没有标注的情况下,还能从训练中提取差异信息。像音高、长度、能量都可以从数据中提取,另外,还能提取一些不易描述的潜在信息。
3.6 适配 TTS
使用适配 TTS 技术,可以为任何发音人合成语音,常被用于配音、声音克隆、自定义声音,是非常热门的研究领域。包含之前统计参数合成、以及最近的一些语音克隆挑战比赛。通常源模型是支持多发音人的 TTS 模型,通过少量数据适配,训练出针对新发音人的模型。
通常将其分成通用适配(提升通用模型)和有效适配(),如下图所示:
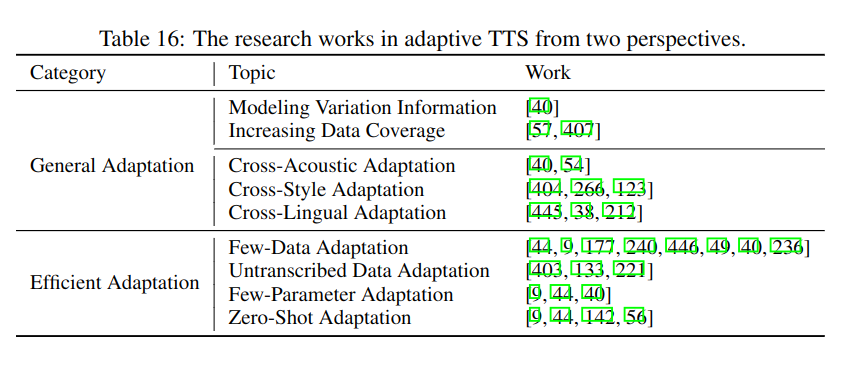
3.6.1 通用适配
通用的源模型
目标是为了提升源模型。一般情况下在训练过程中,没有包含韵律、单色、录音环境的标注,因此训练出的模型容易对训练集过拟合,缺乏泛化能力。于是使用在训练时将必要的声学特征作为输入,将记忆力变为泛化力;以及使用多样性的数据训练的方法。
交叉领域适配
实现了在不同语言之间转换,如使用英文发音者实现中文普通语的语音合成。AdaSpeech 设计了对不同录设备、环境噪声、噪音、语速、音色等声学条件的建模方法。
3.6.2 有效适配
一般情况下,更多的数据使用模型达到更好的语音效果,但也造成更大的花费。利用适参数,通过对整个模型或部分模型的精调(fine-tune),有效适配的目标是尽可能少的数据和参数达到较高的适配效果。基本分为以下四类:
- 更少数据适配
只使用少量文字语音数据精调模型,从几钟到几秒钟不等,甚至是小于二十个句子。
- 更小参数适配
在需要适配多个发音者的情况,需要让语音占内存较小的情况下达到较高音质。例如 AdaSpeech 提出了对条件层归一化生成参数,只需要精调该层参数就可以达到较好的适配效果。
- 未转录的数据适配
在很多场景之中,只有语音数据,比如在线会议,AdaSpeech2 利用这些语音数据实现重建和潜在的对齐,Inoue 等人提出使用 ASR 方式识别语音数据,然后使用转录的数据对进行语音适配。
- zero-shot 适配
对没有目标发音人语音数据的情况下,利用参数来实现适配,这种方式在目标发音人和源数据发音人差异较大时效果不好。
4. 资源
此处总结了一些 TTS 资源,包含开源项目、教程、比赛和语料库。
5. 未来方向
高质量的语音合成
高质量的语音是语音合成的目标,它涉及清晰度、自然度、表现力、韵律、风络、情况、健壮性、可控等方面。
- 能力更强的语音生成模型
- 学习更好的表征,以提升模型效果
- 合成的健壮性,解决重音、跳音、长语音,提升泛化性以适应不同领域
- 表现力/控制/转移,让模型捕捉更多内在信息,以实现控制和转移
- 与人更相似,在情绪化、风格、自然度方面仍有待提升
有效的语音全成
减少资源占用包含减少收集和标注数据,训练模型和模型服务。
- 精减数据,利用无监督或半监督学习和转移方法,对缺少数据的语音建模。
- 精减参数,神经网络针对高质量的合成常常有数以千万计的模型参数,但在移动端,则需要限制内存和功耗,设计轻量级的模型是重要的应用场景。
- 节能,训练和提供高品质的服务,提升资源利用效率。
参考
语音合成(TTS) 论文优选:Cross-lingual
https://zhuanlan.zhihu.com/p/280705416AI 语音:语音合成,语音识别等语音技术(知乎专栏) https://www.zhihu.com/column/c_1306669801105391616
语音合成论文优选:语音合成综述(2021) https://zhuanlan.zhihu.com/p/395767716
【论文学习】《A Survey on Neural Speech Synthesis》 https://blog.csdn.net/weixin_42721167/article/details/118684294
《A Survey on Neural Speech Synthesis》(63 页,References 400 多篇) https://arxiv.org/pdf/2106.15561v1.pdf