论文阅读_基于动态搏弈的知识图推理
介绍
英文题目:Reasoning on Knowledge Graphs with Debate Dynamics(R2D2)
中文题目:基于动态辩论的知识图推理
论文地址:https://arxiv.org/pdf/2001.00461.pdf
领域:图神经网络, 知识推理
发表时间:2020
出处:AAAI 2020
被引量:6
代码和数据:https://github.com/m-hildebrandt/R2D2
读后感
- 针对问题:基于图的自动知识推理
- 目标:提升对真命题和伪命题的识别,提升可解释性
- 结果:对于分类和链接预测任务均有良好表现,且实现了一些归因。
- 核心方法:
- 利用动态辩论的强化学习算法。
- 这是一个相对白盒的方法
- 采用两个 agent 的对抗,一个找真命题相关路径,一个找假命题相关路径,使用知识图中的路径作为参数生成特征,最终由判别器做出判断推理的真伪。
- 具体模型:深度学习模型,两个 Agent 使用 LSTM,判断使用 MLP
- 难点:对抗学习应用于图论和知识推理。
- 泛读后理解程度:60%
(看完题目、摘要、结论、图表及小标题)
精读
(只翻译了实现部分)
3. 方法
文中方法由三部分组成:一个分类器 judge 和两个 agent。agent 用于在知识图(KG)中寻径,两个 agent 分别寻找支持各自论点的证据:基于逐渐训练的模型,决定在每一个 node 上如何选择下一跳;并将每一跳记入当前路径;所有路径都作为 judge 判断的依据,来训练和预测推理是否为真。
如图 -1 所示:
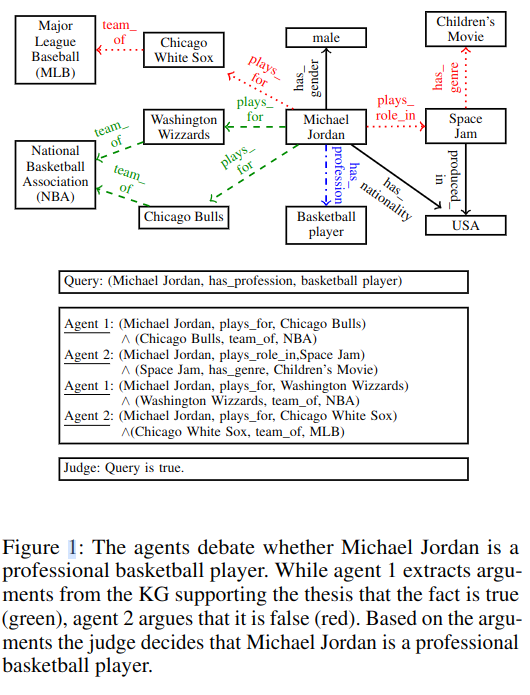
图中各种颜色的线都是已存在的边 edge,其中蓝色线是 judge 的推理:Jordan 是不是专业的篮球运动员;绿色的边是 agent1 找到的认为该假设成立的证据;红边是 agent2 找到的认为该假设不成立的证据。
可以看到,模型通过训练(包括 judge 判断子模型、两个 agent 子模型寻径的方法,都学习成网络参数)。最终模型不仅能做出推理,且能展示推理相关的证据链。
其推理如下:
States
将可观察的状态定义为 S,每个 agent 在某个时点的状态定义为 e,t 为时间点,i 指定是哪个 agent,q=(s,p,o) 是一个三元组,s,p,o 分别指主谓宾。将状态定义为:
\[ S_t^{(i)}=(e_t^{(i)},q) \]
Actions
将在状态 S 时所有可能的动作定义为 A(原地不动也是一种动作 self-loops),它包含所有从 e 点出发的边和相关的目标结点,A 定义为:
\[ A_{S_t^{(i)}}=\{(r,e)\in R\times\xi:S_t^{(i)}=(e_t^{(i)},q)\land(e_t^{i},r,e)\in Kg\} \]
Environments
将环境定义为:agent 动作更新状态的过程
Policies
将 agent 一系列的行为定义为策略。第一步仅是一个主谓宾三元组,而后每一步根据其动作和上一步的状态来决定,通常将每个 agent 的动作历史通过 LSTM 编码。
\[ h_t^{(i)}=LSTM^{(i)}([a_{t-1}^{(i)},q^{(i)}]) \]
其中的动作 a 也隐含了之前的状态,q 是对三元组的编码。实体和关系嵌入是每个 agent 特有的,在训练和搏奕过程中学习。
将每一步每一个动作可能的概率分布定义为 d:
\[ d_t^{(i)}=softmax(A_t^{(i)}(W_2^{(i)}ReLU(W_1^{(i)}h_t^{(i)}))) \]
其中 A 包含了 S 状态所有可能的潜在行为。
最终训练出的策略,就是上述公式中学习到的一系列模型参数。
Debate Dynamics
动态辩论,φ(q) ∈ {0,1}是 agent 针对三元组 q 得出的结果,agent1 尽量找到结构为 true 的三元组,agent2 则相反。设共辩论 T 次(上例中辩论了两次),用τ 表示论据。
The Judge
送别器由两部分组成,第一部分是二分类器,第二部分用于评价论据的质量,并将结果回传给 agent,以供 agent 调参,使 agent 通过训练更好地寻找证据。
模型结构如下:
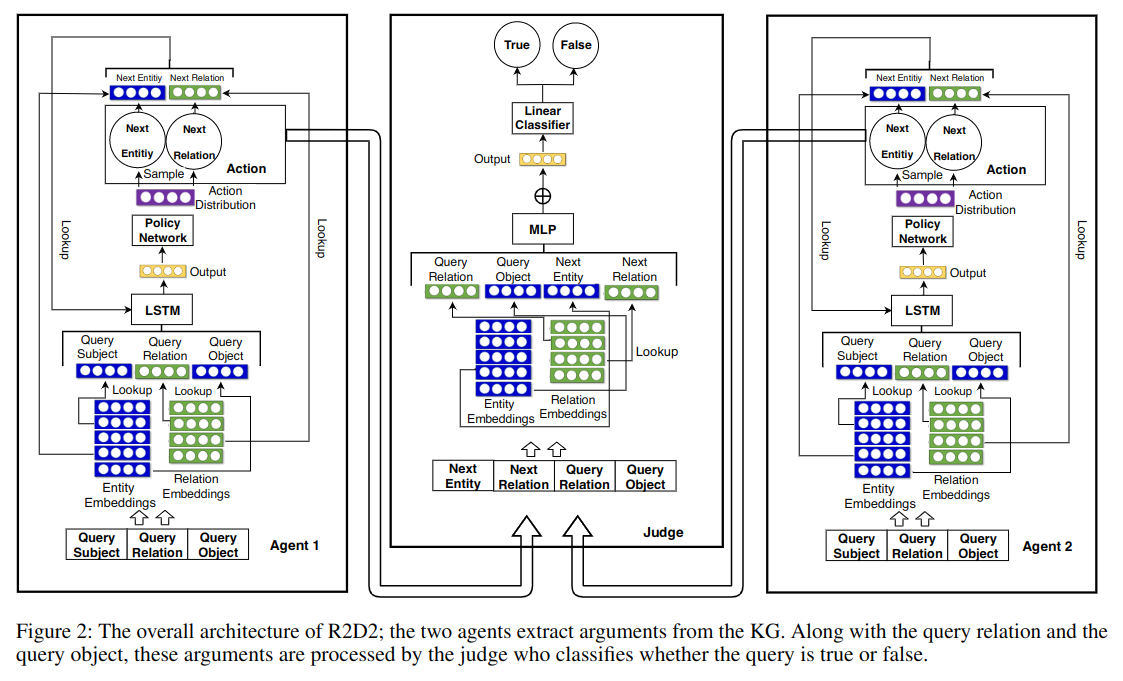
对于每一步 (第 n 步)计算判别结果 y。
\[ y_n^{(i)}=f([\tau_n^{(i)},q^J]) \]
需要注意的是,这里的判断不是根据 q 的主谓宾做出的,而是根据 agent 的行为做出的。
最终,对所有步的综合得分如下,它加入了每个 agent 每一步的 y:
\[ t_\tau=\sigma(w^TReLU(W\sum_{i=1}^2\sum_{n=1}^Ny_n^{(i)})) \]
损失函数使用交叉熵:
\[ L_q=\phi(q)log t_{\tau}+(1-\phi(q)(1-logt_{\tau}) \]
在训练过程中,优化每一步的损失,并使用 L2 惩罚以避免过拟合。
Reward
为了给每个 agent 更多反馈信息,judge 可以分别计算两个 agent 的 t。
Reward Maximization and Training Scheme
反馈最大的训练方案:文中利用强化学习来最大化 agent 的累积反馈,信息增益是反馈 R 的累积。
构建 KG+,它包含在 KG 中未观察到的三元组,其基本原理如下:由于 KG 只包含真实事实,因此,创建负标签的数据集。对 (s,p,o)∈KG,生成 (s,p,!o) 构造 KGc。KG+:=KG ∪ KGc。(我理解好像是以此方法构造反例)。
另外,优化的方法还包括:在开始迭代时先冻结 agent 的权重,先训练 judge 的权重;用移动平均线减少误差;用正则化强化探索等。
一些问题
看论文过程中一直没太明白,为什么可以根据图中的红色边 + 绿色边,就能推断蓝色边?我觉得可能是:传入模型的是 node 和 edge 的嵌入(比如:一开始可能是词嵌入或者图嵌入),如示例中所示:Jardan 是专业的蓝球运动员(蓝色),可以通过公牛队,NBA(绿色)这些词嵌入得到职业的相关性;而明显与儿童电影,棒球(红色)相关的职业相反;黑色的性别、国籍则与之无关。