SHAP解释模型二
SHAP 解释模型(二)
本文在 SHAP解析模型 之后,又尝试了一些 SHAP 新版本的进阶用法,整理并与大家分享.
1 环境配置
以下实验使用当前最新版本 shap:0.41.0,同时安装 xgboost 作为预测模型,并使用较高版本的 matplotlib(低版本有时画图报错).
1 | $ pip install shap==0.41.0 |
2 实验数据
仍延用波士顿房价数据集,由于有些方法需要 explainer 对象,因此构造了 shap_value_obj
1 | import shap |
3 单特征实验
首先,尝试一些单特征分析方法.
3.1 分析单个实例
在图中主要关注 base_value,它是预测的均值,而 f(x) 展示了该实例的具体预测值,红色和蓝色区域的颜色和宽度展示了主要特征的影响和方向.
1 | shap.force_plot(explainer.expected_value, shap_values[0,:], X.iloc[0,:]) |

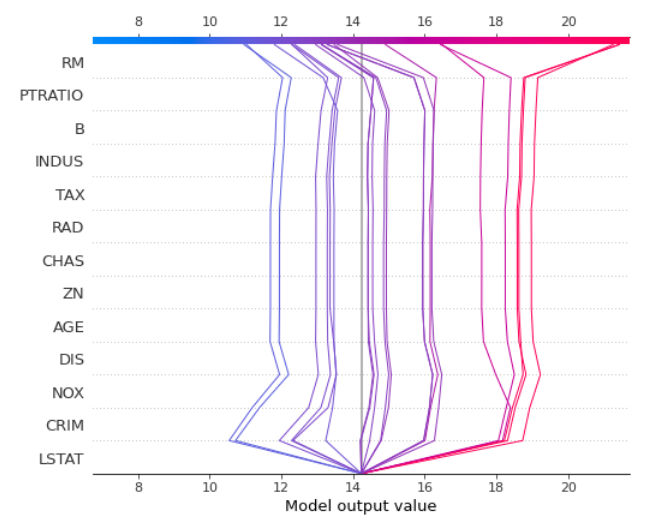
3.2 决策图
决策图可在一张图上展示多个实例的特征对结果的影响,一般情况下,位置越靠上的特征影响越大.本例中设定 feature_order='hclust',则是按 shap value 进行聚类,再按特征的相关度排序,因此线条看起来比较直;其 x 轴描述的是各个特征对最终预测值拉扯的方向和力度.
使用该方法也可以用于异常值检测,如果有一条线明显与其它线的方向不同,则可能是异常值.
1 | features = X[:20] # 只分析前20个样本 |
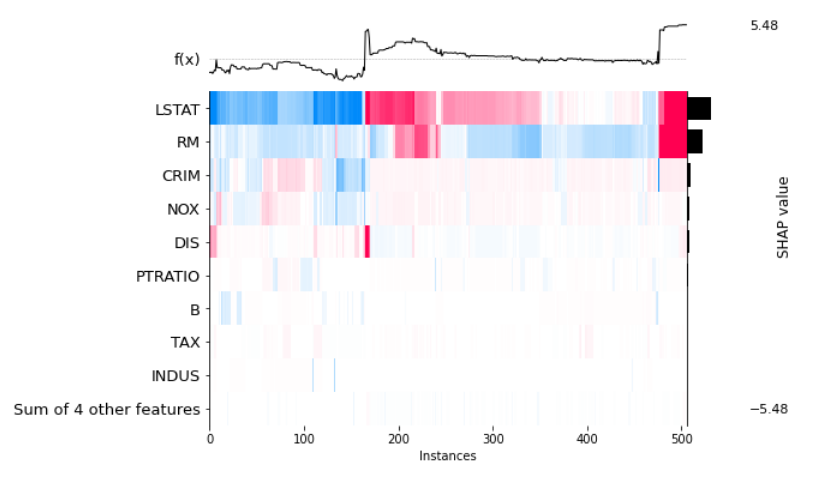
3.3 热力图
热力图的横轴是每个实例,纵轴是每个特征对该实例的影响,用颜色描述该特征对该实例的影响方向和力度,比如 x 轴在 300 附近的实例,其预测值 f(x) 在 0.5 附近,原因是 LSTAT 对它起到正向作用,而 RM 对它起负向作用,其它特征影响比较小(浅色).
1 | shap.plots.heatmap(shap_values_obj) |
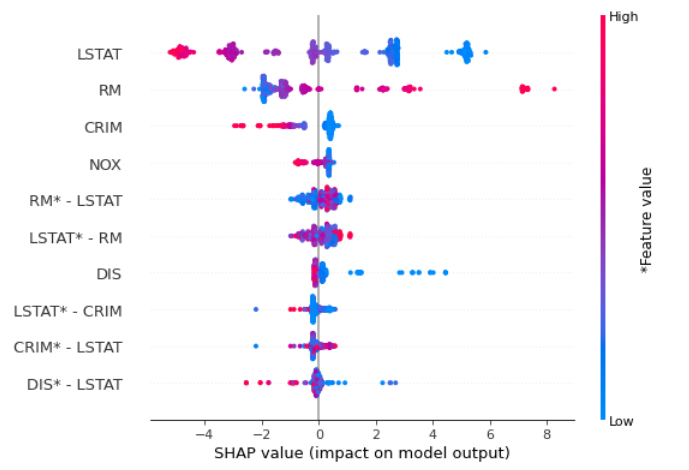
4 特征组合实验
特征组合是数据分析的重要因素,下面实验对特征组合的挖掘方法.
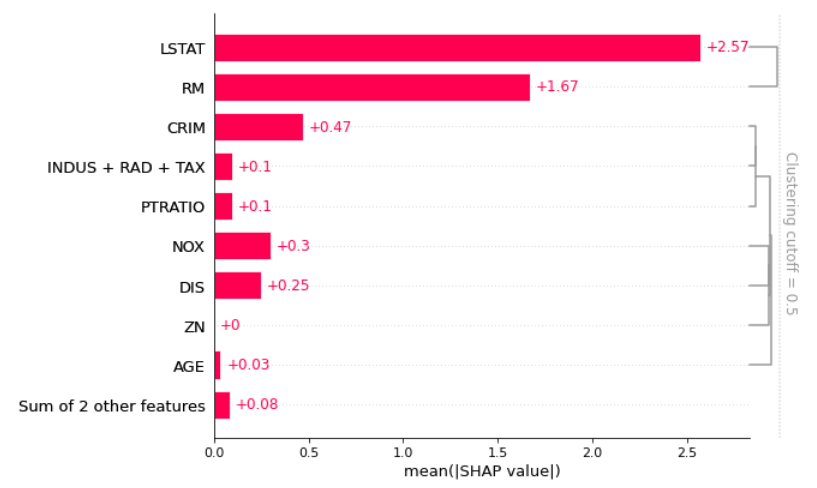
4.1 带聚类的特征图
先对 shap value 做聚类,此时 shap_value 值类似的实例被分成一组,相关性强的特征就能显现出来,再画条形图时,展示了特征的相关性.
1 | clustering = shap.utils.hclust(X, y) |
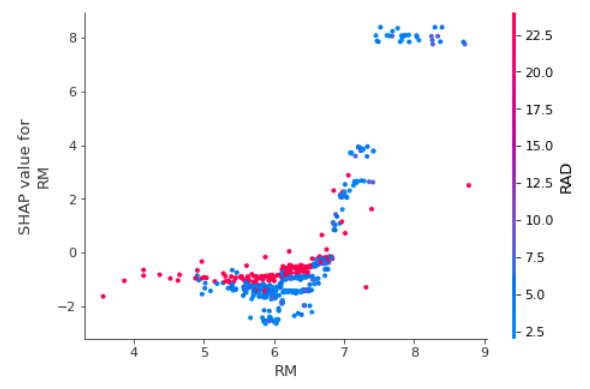
4.2 依赖图
依赖图分析一个特征对另一个特征的影响,示图类似 shap 散点图,横坐标为特征 "RM" 的取值范围,纵坐标为其取值对应的 shap value,颜色分析的是另一特征 "RAD" 在 "RM" 变化过程中的分布.
1 | shap.dependence_plot("RM", shap_values_obj.values, X, interaction_index='RAD') |
4.3 交互图
交互图对角线上展示的是该特征与预测值的关系,它与最普通的 shap plot 相一致,对角线以外其它位置是特征两两组合对预测的影响.每个子图的横坐标为 shap value,也就是说,子图越宽,该特征组合对结果影响越大.
1 | shap_interaction_values = explainer.shap_interaction_values(X) |
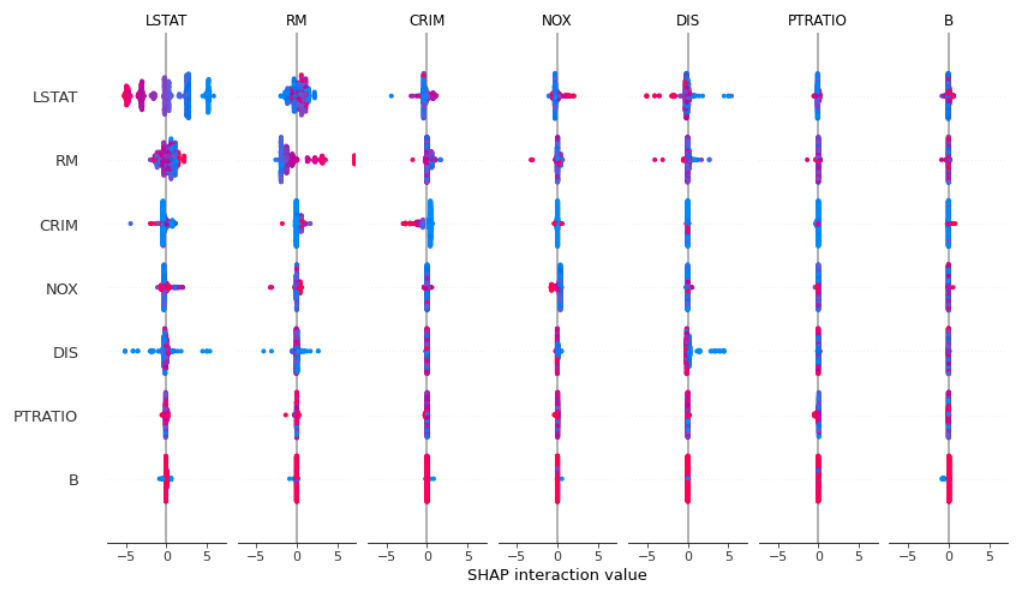
4.4 特征组合的影响
将交互图按特征重要性排序后绘图.个人认为下图非常有用,它将单特征与特征组合画在一张图中,可以从中分析出哪些特征组合更为重要.
1 | shap_interaction_values = explainer.shap_interaction_values(X) |