Skill 怎么用
1 Skill 是什么
我们在使用大模型时经常会遇到一个问题:做同一类工作时,每次都得重新把要求说一遍,中间还要反复修很多细节。这本身也是一种重复劳动。把它写成 prompt 存起来,后面每次再复制粘贴,其实也挺麻烦。这种场景就特别适合用 skill,把我们从细节和重复里解放出来。
自从开始用 skill 之后,就有点停不下来了。开始是在用别人写好的,后面慢慢把自己常用的流程和与大模型的交互沉淀下来。把触发条件、步骤、边界,还有要调用的工具写进固定目录里,下次再遇到同类任务时,基本就不用重新理解一遍了。
越来越觉得,skill 真正解决的不是“模型不会做”,而是“同一种事总在重复解释”。一个流程只要已经比较稳定,就值得把它沉淀下来。这样后面复用的就不只是那几句提示词,而是一整段已经跑顺的执行链条。
大致做下来,其实也就是三步:定义 skill、调用 skill、持续迭代。
2 自己写一个
2.1 写 SKILL.md
在自己的技能目录下:
1 | mkdir mytest |
skill 一般由两部分组成:开头的 YAML 元数据,加上后面的 Markdown
指令。元数据里最关键的是 name 和
description,这两个最好一开始就写清楚。
1 | --- |
3 怎么调用
3.1 直接调用
最直接的方式就是写 skill 名字,手动调用。
1 | /mytest doc/design.md |
3.2 自然语言调用
也可以先让 agent 扫一遍当前项目里的 skills,后面直接用自然语言说需求。只要 skill 的名字和 description 写得够清楚,很多时候它会自己挑对。
比如直接说:为这篇文章生成 Markdown 文件头。
3.3 实际感受
比较让我意外的是,它有时会顺着上下文猜到我要做什么,然后主动帮我补一个 skill,而且经常还真是我会反复用到的那种。很多都不是写代码本身,而是我平时反复在做的事务性工作。
它之所以会猜得这么准,大概率就是因为这些流程在我的使用习惯里已经足够稳定了。
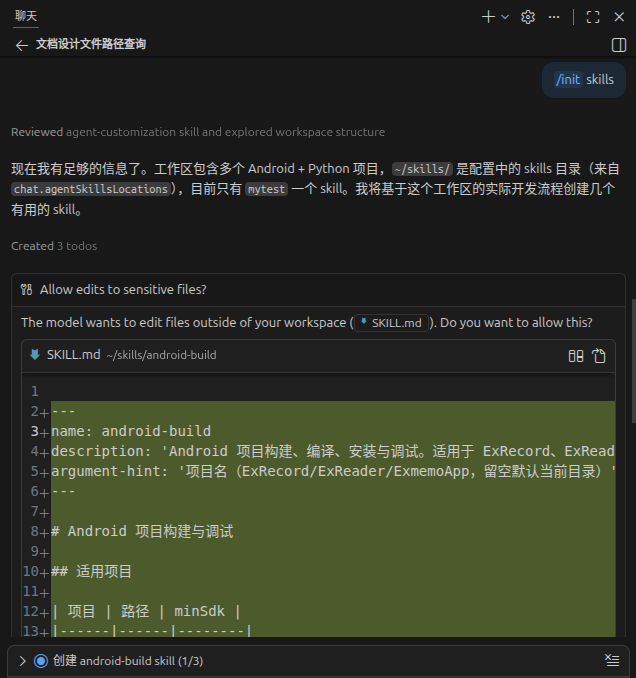
4 装别人的 skill
4.1 find-skills
find-skills 不是内置 skill,它是 Vercel Labs 做的第三方
skill。可以把它理解成一个帮你发现并安装其他
skill的“技能管家”。
它基于 Node.js,所以要先有 Node.js 环境。先安装 Node.js(如果还没装):
1 | # Ubuntu/Debian 系统 |
安装 find-skills
1 | npx skills add https://github.com/vercel-labs/skills --skill find-skills |
- 选择安装目标:系统会列出它检测到的 AI 编程助手,按自己的使用环境选就行。
- 选择安装范围:
- Project (项目):技能只对当前文件夹下的这个项目生效。
- Global (全局):技能对你电脑上的所有项目都生效。
4.2 用它找 skill
命令行里可以这样用:
1 | npx skills find "skills关键词" |
也可以直接在聊天框里打字,比如:帮我找下“小红书”相关的 skill。我自己更偏向这种用法。因为有些内容直接搜不到时,agent
往往会顺手换几个近义词再搜,成功率会高不少。
4.3 常用命令
1 | npx skills list # 列出技能 |
5 复杂 skill 怎么做
如果要做复杂一点的 skill,我更推荐用
skill-creator。它本身也是一个 skill。
5.1 为什么用它
直接在聊天里用自然语言描述,也能让 agent 帮忙生成
skill。那为什么还要专门用 skill-creator?
简单的 skill,比如只有 3 到 5
个步骤的,直接对话生成通常就够了。再复杂一点的,就更适合交给
skill-creator。
skill-creator
会主动问你一系列结构化的问题,像填表一样带着你往下走:
- Skill 的名字是什么?
- 它应该在什么场景下触发?
- 需要执行哪些具体步骤?
- 需要处理哪些边界情况?
一个完整的 skill 不只是
SKILL.md,还可能带上配套脚本(.js、.py)、配置文件、示例文件和说明文档。
另外,它还会顺手检查 YAML 格式对不对,description 写得清不清楚,skill 能不能被 agent 正确识别。
如果只靠纯对话来回调试,当然也能做。但一旦 skill 不工作,就得把错误信息贴出来,再让 agent 帮着分析,通常要来回折腾好几轮。
5.2 怎么安装
1 | npx skills add anthropics/skills@skill-creator -g -y |
6 哪些值得做成 skill
如果说 agent 更擅长理解目标和编排流程,那 skill 更适合承接那些已经相对稳定、值得反复复用的部分。
我现在更倾向把下面几类事情做成 skill:
- 会重复出现的任务
- 输出比较明确的任务
- 需要接浏览器、API 或本地工具的任务
- 需要固定确认点和权限边界的任务
这类任务一旦跑通,复用价值通常就很高。真正省下来的,不只是提示词,而是整套执行链条。
6.1 先别急着做的
反过来,有些事一开始就不适合硬做成 skill:
- 一次性的任务
- 强依赖临场判断的任务
- 目标一直在变、流程还没收敛的任务
- 需要大量人工兜底的任务
这类场景更适合先靠 agent 对话、人工协作和半自动流程来完成。等任务边界稳定下来,再看是不是值得沉淀成 skill。
7 最后
skill 最适合沉淀那些已经跑顺、后面还会反复出现的工作。先把流程做对,再把它写成 skill。这样省下来的,不只是每次重打一遍提示词,而是少了很多重复沟通和重复判断。