论文阅读_基于知识图谱的约束性问答
读后感
- 针对问题:利用当前的知识库 (KB),回答用自然语言提出的问题。
- 目标:一方面开发用于评价约束性问答的数据集;另一方面开发针对约束性问答的解决方法。
- 结果:产出评测数据集;提出的多约束查询图算法提升了对复杂问题的解答能力。
- 核心方法:
- 复杂问题的分类和处理机制,抽象出六种约束类型,以及对应各类问题的解决方法。
- 方法
- 找到问题相关实体节点
- 找到满足约束的所有路径
- 将与问题语义相似度最高的作为答案
- 难点:整个过程中约束到底如何产生作用。
- 泛读后理解程度:直接精读
(看完题目、摘要、结论、图表及小标题)
介绍
英文题目:Constraint-Based Question Answering with Knowledge Graph
中文题目:基于知识图谱的约束性问答
论文地址:https://readpaper.com/paper/2572289264
领域:图神经网络、问答系统
发表时间:2016
出处:acl
被引量:142
代码和数据:https://github.com/JunweiBao/MulCQA/tree/ComplexQuestions
阅读时间:2022.03.20
摘要
WebQuestions 和 SimpleQuestions 是近年来常用的基于知识的问答系统(KBQA)数据集,它们之中大多是简单问题,即在现成的数据三元组中就能找到答案,它们缺乏对复杂问题的评价能力。为此,文中提出建构新的数据集,用于评价需要多种知识相关性才能得到答案的复杂问题。另外,文中提出 KBQA 方法来解决多约束问题。相对于现有方法,文中方法在现有的两个基准数据集上获得了与之前模型差不多的结果,并在复杂问题上取得了显著的改进。
1. 引言
基于知识库的问答任务(KBQA)是:利用当前的知识库 (KB),回答用自然语言提出的问题。Freebase 是个类似 wikipedia 的网站,在本文中被用做待查的知识库。WebQuestions 和 SimpleQuestion 两个数据集常被用于评测 KBQA 问题。
WebQuestion 是 85% 的问题,以及 SimpleQuestion 中的所有问题都是“简单”问题。所谓简单问题是使用单个关系链接就可以回答的问题(主谓宾三元组),如图一上图中所示的问题。
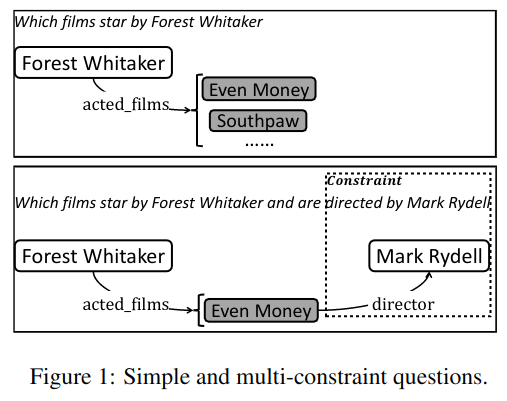
图一中的下图则是复杂问题,它用两个条件得出一个结果。其中的“多约束”是指包含用不同表达式表示的多个语义约束,以限制答案集。回答此类问题需要结合多种关系。
论文的两个主要贡献是:
- 系统地提出了解决多约束问题的方法:将多约束问题(MulCQ)转换成多约束查询图 MulCG。
- 建立新的 QA 数据集 ComplexQuestions,用于评测多约束问题。且文中模型在复杂数据集上有显著提升。
2. 多约束问题
2.1 约束的分类

多约束问题被定义为需要多个连接或者需要特殊转换才能找到答案的问题,将其分为六大类:
多实体约束:一个问题涉及多个实体,比如表 -1 中问题 1 的 "Forest Whitaker", "Mark Rydell" 共同限制了答案。
类型约束:问题中指定了答案的类型,比如表 -1 中问题 2 限制了回答的类型为 City。
显性时间约束:显示地约束了时间,如表 -1 中问题 3 限制了 2012 年,这种问题很常见。
隐性时间约束:隐性地约束了时间,如表 -1 中问题 4 限制时间在南北战争开始时,处理时需要先将期变换为显性时间,这类约束常出现在从句中。
顺序约束:问题答案通常需要通过排序才能得到,一般在问题中用最高级短语描述排序规则,如表 -1 中问题 5,回答时需要先对中国河的长度进行排序。
聚合约束:这类问题通常需要通过统计求出,比如表 -1 中问题 6 问个数。
2.2 选择问题构建复杂问题数据集
使用以下步骤筛选基于 FreeBase 能找到答案,且为多约束的问题,然后进行人工标注。
首先,取 2015.1.1-2015-4.1 搜索引擎三个月的问题,它们满足以下两个条件:不包含代词;问题长度在 7-20 个单词之间,这是因为问题太短一般不包含约束条件,问题太常又难以回答。进一步采样其中的 10%,使用实体链接方法来检测实体,去掉不包含实体的问题;去掉除了实体和停用词不包含其它词的问题;最后将问题分类如下:
问题至少包含两个不重叠的实体
问题包含 FreeBase 中的类型短语
问题包含 NER 可识别出的时间日期
问题中包含关键字,如“when”,"before","after","during"
问题中包含 WordNet 中的最高级短语或序号
问题中包含对个数的提问。
问题可以包含一个或多个约束,满足条件的有上万条问题,根据其分布筛选问题,然后根据 FreeBase 中的知识进行手动标注,最终获取了 878 个问答对。
2.3 问题说明
最终发布的复杂问题数据集,包括 2100 个多约束问题答案对,包括下面三种来源:
596 个从 WebQuestions 训练集中选择,326 从其测试集中选择。
300 个在 2015 年由 Yin et al... 发布
878 个基于上一节的方法标注
将其分成训练集 1300 和测试集 800 两部分。
3. 定义
3.1 知识库
用 K 表示知识库,以三元组 triple(t) 的方式组织数据,比如主语 subject(s) 是 BarackObama,谓语 predicate(p) 是 birthday,宾语 object(o) 是 1961。主语和宾语一般是实体或者数值,谓语常用于描述关系。
3.2 多约束查询图
首先定义四种元素:
节点:
文中定义了两种类型的节点,已知的恒定节点(方)和未知的可变节点(圆)。
边:
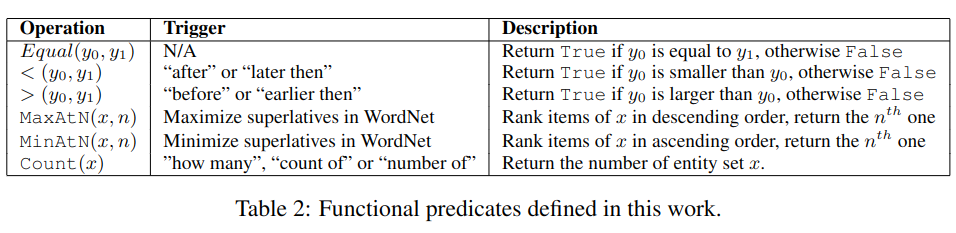
文中定义了两种类型的边,关系边和功能边,上例中的动词 birthday 是关系边,功能边用于表示大于小于等函数关系,如表 -2 所示:
基本查询图:
基本查询图定义为 (vs,p,vo),vs 表示问题中给出的恒定的节点,vo 是可变节点,它隐藏在答案之中,p 是连接两者的路径,它可能由一条边或多条边构成。
约束:
约束定义为三元组 (vs,r,vo),vs 是恒定节点,vo 是可变节点,r 是功能边,实例化后,vo 与实体 vs 需满足关系 r。
MulCG:
Multi-constraint query graph 多约束查询图,MulCG 基于基本查询图 B,它包含一个问题和一系列的约束 C={C1,...CN},最终输出符合条件的图 gN,它满足所有约束。
从基本查询图的恒定节点开始,根据约束,遍历所有的可变节点,整个过程中所有被连接的实体关系都应满足相关性关系以及常识。
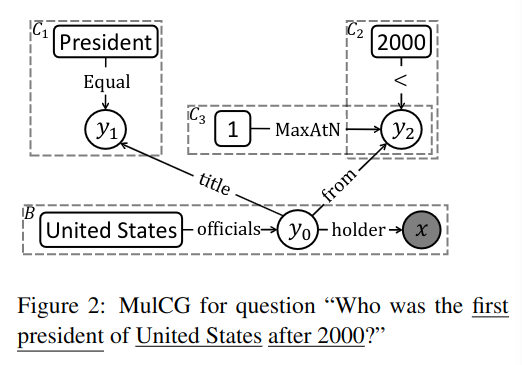
图 -2 展示了 MulCG 的一个示例,文中的恒定实体是 United States,可变实体是 x 和 y,两条边为 officals, holder,三个约束分别为 C1=(President,Equal,y1),C2=(2000,<,y2),C3=(1,MaxAtN,y2)。注意,不同的约束顺序可能造成不同结果。
4. 方法
问题定义如下:将多约束定义为 Q,知识定义为 K,将问题解析成一系列约束 H(Q),对于每一个 g ∈ H(Q),得到节点的特征 F(Q,g),通过排序,得分最高分结果作为答案。
4.1 生成基本查询图
搜索问题中提到的实体,将每个实体 s 作为恒定节点,基于知识图,搜索 s 相关的路径(限定跳数),建立基本查询图一跳 (s,p0,x) 或两跳<s,p1-yout-p2,x>,yout 和 x 都是可变节点,x 为最终答案。
使用基于卷积网络 CNN 的模型计算问题与基本查询经过路径的相似度,此部分将在 4.4 详述。
4.2 约束检测和绑定
一个基本查询图只对应一种关系,对于多约束,需要将所有约束逐条加入,每一条约束具体又包含约束搜索和约束绑定。
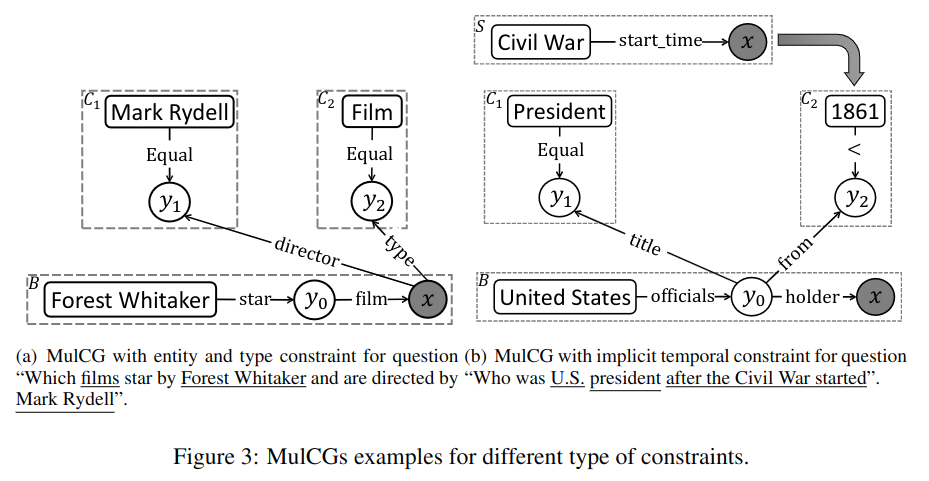
(1) 实体约束
对实体的约束常作为恒节点,比如图 -3(a) 是一个多实体问题,Forest Whitaker 和 Mark Rydell 指向不同实体,最初生成的基本查询图是 g0=B,然后,搜索到了约束 1:C1=(Mark Rydell, Equal, y1),然后将边 director绑定到 g0,从而,将变量节点 Ci 与 gi-1 通过路径相连。
约束可以让任何节点与基本查询图连接;对实体的约束绑定,常常用于解决消歧问题。
(2) 类型约束
对答案的类型约束常常由名词给出,比如图 3-a 中的“film”就是类型约束。搜索时,对于知识的类型,构建了形如 C2=(film,Equal,y2) 的类型约束;绑定时,类型限制加在可变节点上,该节点具有边类型的答案。
(3) 显性时间约束
时间约束常常描述为介词短语或从句中的数字,如 "after 2000",图 -2 中,from 连接了 y0 和 y2,函数约束 C2=(2000,<,y2),它筛选了 y0 相关实体中大于 2000 的子集。先搜索时间短语,比如 2000,小于号通过表 2 中字典建立约束 Ci=(t,r,y1);搜索到时间约束后,如果知识图中有路径 p 连接的实节满足条件,则将约束绑定关系。
(4) 隐性时间约束
图 -3(b) 中描述的 " 南北战争之后 " 触发了隐性时间约束,它使用了时间状语从句。由于命名实体识别不能识别隐性时间约束,因此使用预定义词的方式搜索,然后将其转换成显式时间约束;绑定方法与显性时间约束一样。
(5) 顺序约束
顺序约束通常通过形容词或副词的数字和最高级形式表示,比如图 -2 中的 first,通过对答案中节点的排序的 MaxAtN 函数,得到最终结果。搜索使用 WordNet 中提取的序列数表和最高级表来检测关键词,再用数学函数来计算约束 Ci=(n,op,yi);如果与边相连的可变节点满足条件,使用词嵌入与最高级词最相关的词绑定路径,如此例中使用 from 绑定。
(6) 聚合约束
当问题以 "how many" 开头,或者包含 "number of", "count of" 等关键字时,实现时需要统计答案节点中的实体个数。
4.3 生成搜索空间
算法 1 描述了生成搜索空间 H(Q) 的过程:

E 是将 Q 作为输入检测到的与之链接的实体集合。
用 s 遍历 E 中实体,将 s 和知识库 K 作为输入,得到所有基本查询图 gb,然后将它们中的每一条都加入 H(Q) 和 T,T 表示临时数据集。
用 gb 遍历临时数据集 T,基于 gb,E,Q,K,找到相关的所有约束 C,Permutation(C) 返回所有可能的约束的索引号,对于每个索引号,试图找到临时数据集中能与之绑定的查询图 gc,将其插入候选集 H(Q)。
4.4 特征和排序
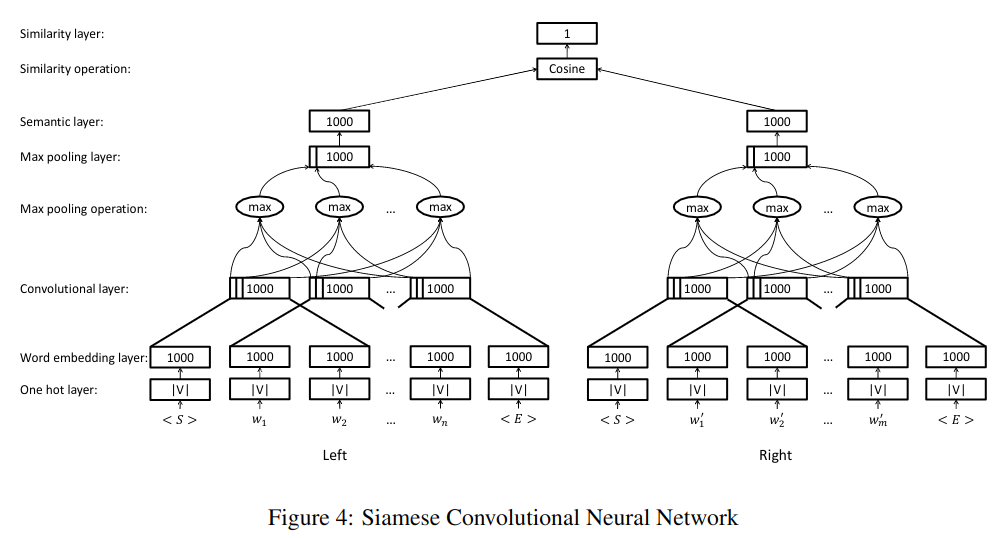
使用孪生卷积网络来计算两个字符序列的相似度,输入是两个字符序列,将它们映射成 k 维的字符向量,与词汇匹配方法相比,连续空间表示方法显示出更好的结果。
对于两个序列 Sl 和 Sr,分别加入了 S 和 E 来标记开始和结束,首先把输入词转换成 one-hot vector,然后查表找到其词嵌入,再通过卷积加入 3 个词的上下文信息得到上下文向量特征,用最大池化来提取最显著的局部特征,生成定长的全局特征,最后用一个多层感知机将池化层转换到语义层,两边分别得到 Hl 和 Hr,然后用 cosine(Hl,Hr) 来计算二者的距离,得到两个序列的相似度。
基于上术 CNN 模型,为基本序列图(Basic Query Graph)设计了表 -3 中的四个特征,为约束也提供四类特征,分别是指示特征 I,计数特征 N,约束搜索特征 V 和约束绑定特征 P。

5. 实验
5.1 设置
使用三个数据集测试,ComplexQuestions(CompQ)是上文中提到的新生成包含 2100 问答的数据集;WebQuestion(WebQ)包含 3778 训练集,2032 测试集,由人基于 Freebase 知识库手工标注;SimpleQuestion(SimpleQ)中每个问题都是人工编辑的知识库三元组。
5.2 结果和分析
实验结果如图 -4 所示,将 STAGG 作为 Baseline:
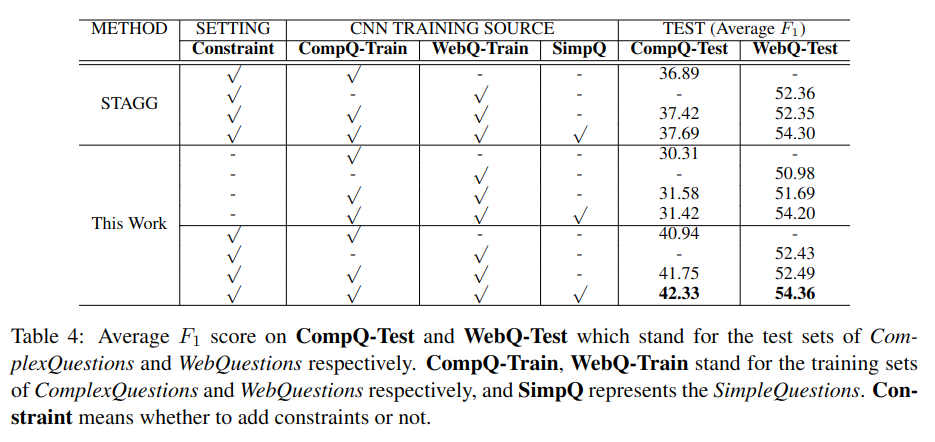
对于简单问题与 STAGG 效果类似,对于复杂的约束问题明显优于 STAGG,尤其是使用了 Constraint 约束训练的模型效果有明显提升,另外,加入了更多的 WebQ 和 SimpleQ 训练数据后,模型效果也有所提升。
6. 相关工作和讨论
2015 年在基于知识的问答 (KBQA) 中,使用字典特征或 CNN 的方法对于简单关系问题就得到了较好的效果。
WebQuestions 和 SimpleQuestion 是两个用于评测 KBAQ 任务的数据集,其中大多数是简单问题。之前的研究也大多针对简单问题展开,近几年也提出一些针对多实体和约束的方法,但并没有具体评估它们的 KBQA 系统,也没有系统地给出多约束问题的解决方案。
7. 总结
发布了 ComplexQuestions 数据集用于评价多约束问题,并提出了 KBQA 方法解决多约束的图问题,且得到了良好的实验效果。