主题笔记_音频大模型
1 介绍
本次分享包含音频压缩,语音识别,语音合成,以及近两年来大模型在音频领域的应用,涉及八篇论文和一个近期 github 霸榜的语音合成工具。
结果如下图所示:(图链接:audio_llm)
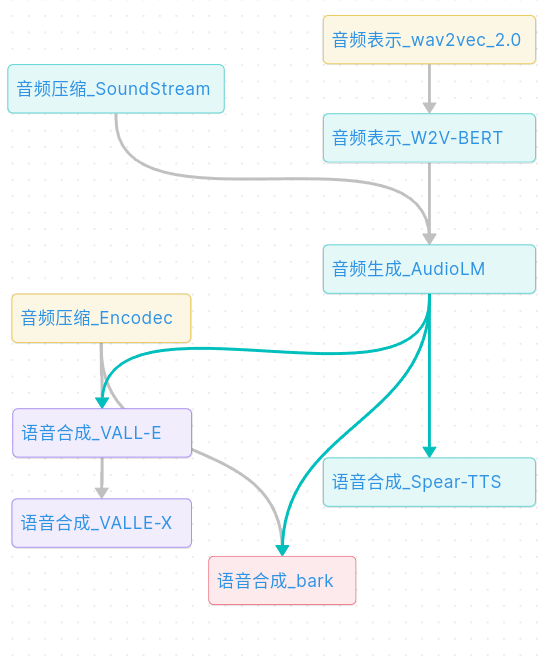
- 共涉及三种主要技术:音频压缩、音频表示、语音合成;
- 主要技术来自:google(绿色),微软(紫色)、Facebook(黄色)、Suno-ai(红色)
- 图中也大致描绘了各技术出现的先后顺序(从上到下)
- 图中线条表示各技术的依赖和包含关系
- 除了最近霸榜 Bark,其它都能找到技术论文,并在下文中进行了简单介绍
2 基本概念
本部分介绍音频领域的基本概念。
2.1 音素
语音中最小的、不可再分的语音单元。在不同语言中,音素数量也有所不同,例如英语中有大约 44 个音素,中文普通话中有约 20 个声母和 38 个韵母。
2.2 语义特征与声学特征
语义特征是指语音合成的内容,如:音调、语速、语调;而声学特征则是指语音的物理属性,如基频、共振峰等。二者在不同场景及文章中定义也不完全一致。可以简单地理解为:语义与文本内容更相关,声学与声音更相关,即:文本 ->语义 ->声学 ->音频。
2.3 傅里叶变换
时域和频域之间进行转换。傅里叶级数则是将周期函数分解成谐波的和的形式。给音频编码、音频压缩、音频降噪等领域的应用提供了基础,同时,也应用于图像处理,时序等领域。
2.4 梅尔倒谱 MFCC
MFCC 是从音频信号中提取语音特征的一种最常用方法。可以用于语音识别、语音合成、发音检测等应用。MFCC 能够提取关于音频信号的有用信息、不受语调改变的影响、对于白噪声的干扰有强鲁棒性。
MFCC 主要分为两步:首先,对音频信号应用快速傅里叶变换(FFT)将其变换到频域。然后在频域中,将频率轴转换为梅尔频率,更好地匹配人耳对声音的感知方式,得到其梅尔倒谱系数,这些系数可以看作是声谱图在梅尔频率轴上的投影。
3 近期主要技术
3.1 音频的表示学习
音频表示学习,指的是用相对短的数据描述音频,可理解为抽取音频特征,一般用于语音合成,语音识别等领域。
3.1.1 wav2vec_2.0
时间:2020-10-22
出处:Facebook AI
贡献:从未标注的语音中学习音频的表示,然后通过少量标注数据精调。该方法一开始用于语音识别领域。
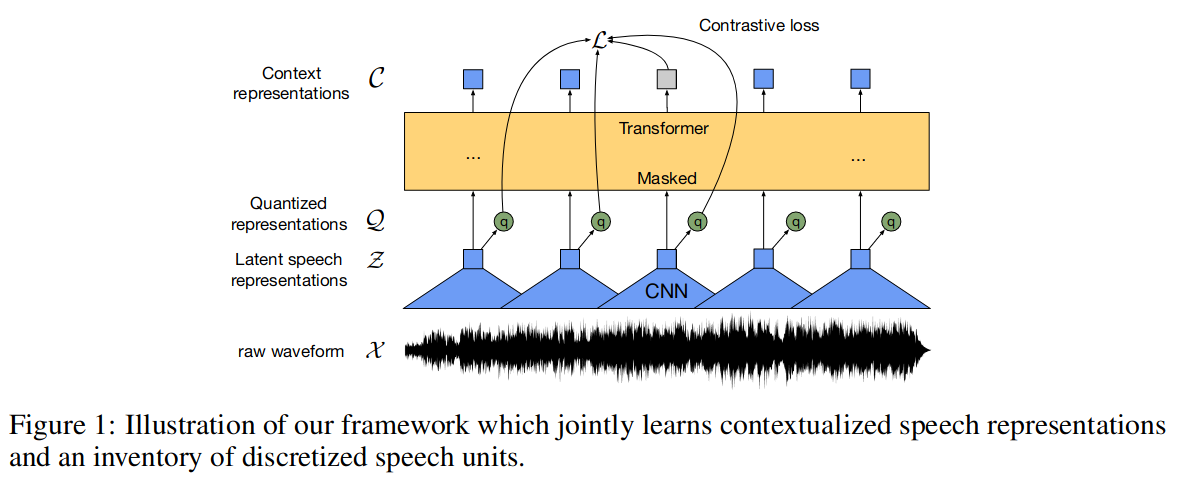
结构:模型结构结合了 CNN 和 Transformer。
模型先使用卷积网络将输入音频 X 映射到隐空间 Z,然后将 Z 送入 Transformer 网络构建表示 C 以便从上下文中提取相关信息;另外特征编码 Z 还被送入量化工具,以生成量化后的表示 Q(离散)。
3.1.2 W2V-BERT
时间:2021-12-13
出处:MIT & Google Brain
贡献:结合了对比学习和 Mask 语言模型,w2v-BERT 效果优于 wav2vec 2.0 30% 以上。
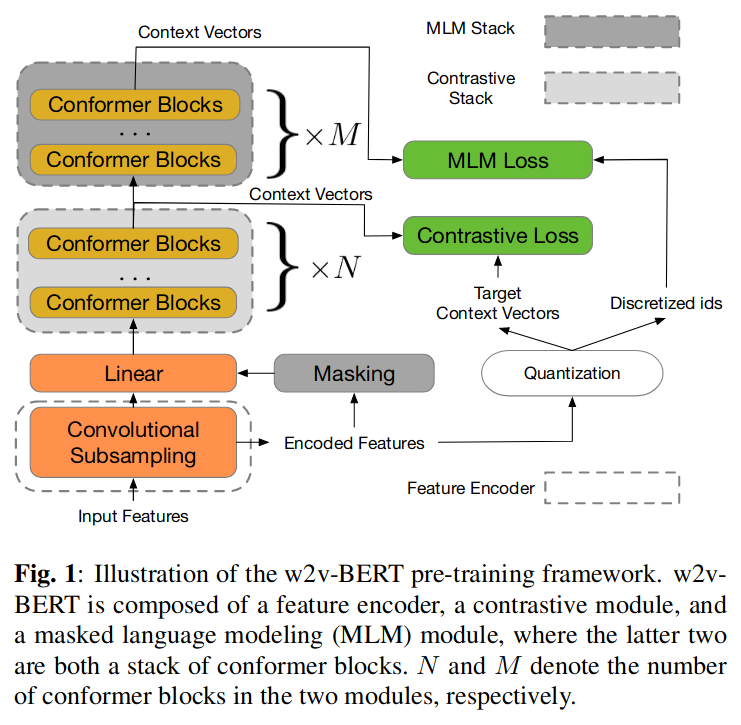
结构:训练了 End-to-end 模型。
特征编码器:由两个 2D 卷积层组成,使声学输入序列长度减少到 1/4。
对比学习模块:包含一个线性映射层,及多个 Conformer 层,每个块都是一系列多头自注意力、深度卷积和前馈层。对比模块涉及量化机制。
Mask 预测模块:使用 BERT 中的 Mask 方式,利用对比学习的输出,学习语音中高层的上下文之间的关系。
3.2 音频压缩和生成
本部分主要介绍基于深度学习的音频压缩技术,除压缩数据以外,该技术还被应用于生成高质量音频。
3.2.1 SoundStream
时间:2021-07-07
出处:Google
贡献:高效压缩语音、音乐和一般音频。
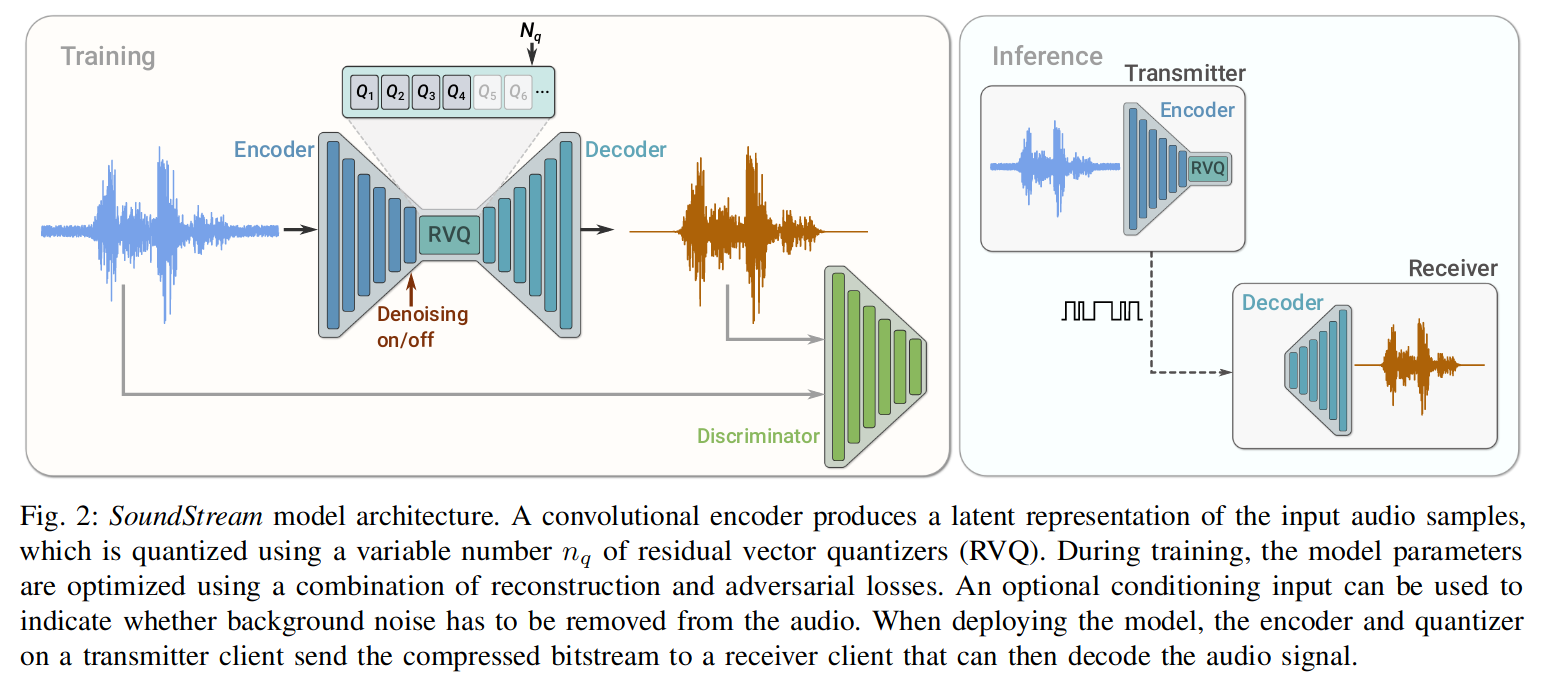
结构:模型由编码器,量化器,解码器组成,主要使用了卷积技术。
模型由组成:
编码器:卷积 Encoder 将采样率为 fs 的输入音频 x 转换为嵌入序列。
残差向量量化(RVQ):将嵌入通过 codebooks,压缩成少量字节(目标位数)的表示,生成量化嵌入。
解码器:从量化的嵌入中产生有损重建 x^。
其训练过程中还使用了判别器 Discrminator,它结合了对抗和重建损失,并使用可选的条件输入,用于指示是否从音频中去除背景噪声(Denosing)。
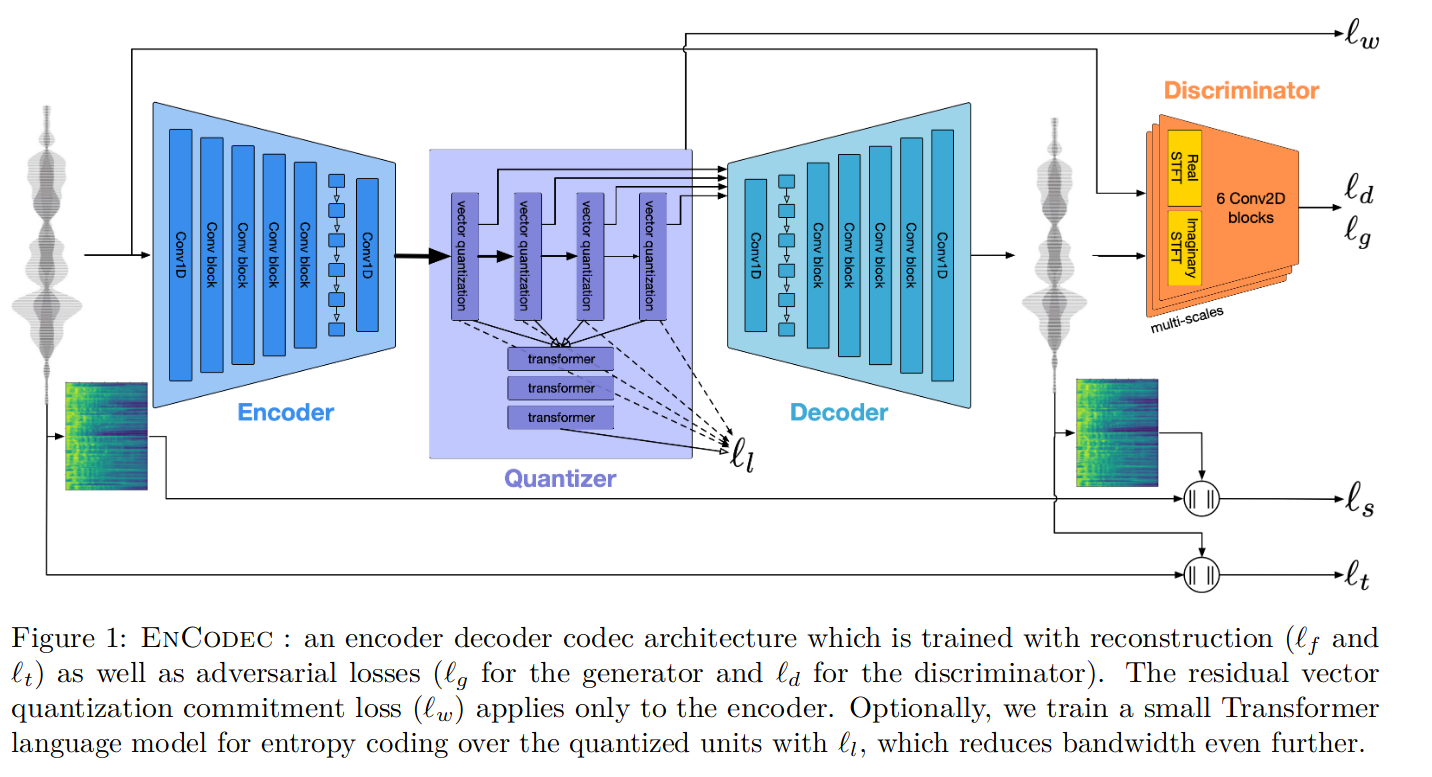
3.2.2 Encodec
- 时间:2022-10-24
- 出处:FAIR Team
- 贡献:相对 SoundStream 使用更复杂精细的结构,效果更好。
- 结构:方法与 SoundStream 相似,模型主要使用了卷积,LSTM,还加入 Transformer 优化量化单元,以减少带宽。模型由编码器,量化器,解码器三部分组成。从图中可以看到,其目标函数考虑了更多因素:重建损失,对抗损失,量化损失,以及 Transformer 损失。
3.3 综合使用
本部分包含了生成音频和文本转换成语音两种主要应用场景。
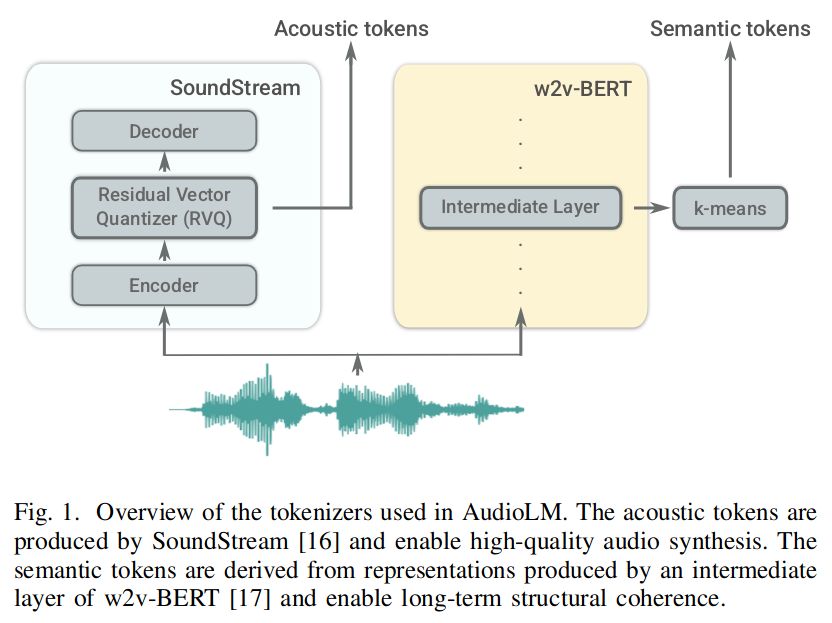
3.3.1 AudioLM
时间:2022-09-07
出处:Google research
贡献:模型用于生成音频,保持一致性和高音质;只需要 3s 语音作为提示,即可生成训练期间未见过的语音,并保持说话人的声音,韵律,录音条件(混响、噪音)。其贡献主要在于在大模型训练中解耦了语义标记和声学标记。
结构:使用无监督数据训练,利用对抗音频压缩,自监督表示学习,语言建模。分层方式结合语义和声学标记;基于 w2v-BERT & SoundStream。其工作过程如下:
将输入音频 x 映射到离散的词表 y:y=end(x)。
使用仅有 decoder 的 Transformer 模型,操作 y,用时间 t-1 预测 t 对应的词(预测阶段使用自回归)。
解码模型,将预测出的 y映射回音频格式。x=dec(y^)
3.3.2 Spear-TTS
- 时间:2023-02-07
- 出处:Google research
- 贡献:文本转语音系统,它是 AudioLM 的延展。多语言的语音合成系统,使用少量有监督数据训练(自监督音频 + 有监督 TTS)
- 结构:基于 w2v-BERT & SoundStream。对于语音数据对儿比较少的小语种做了以下优化:
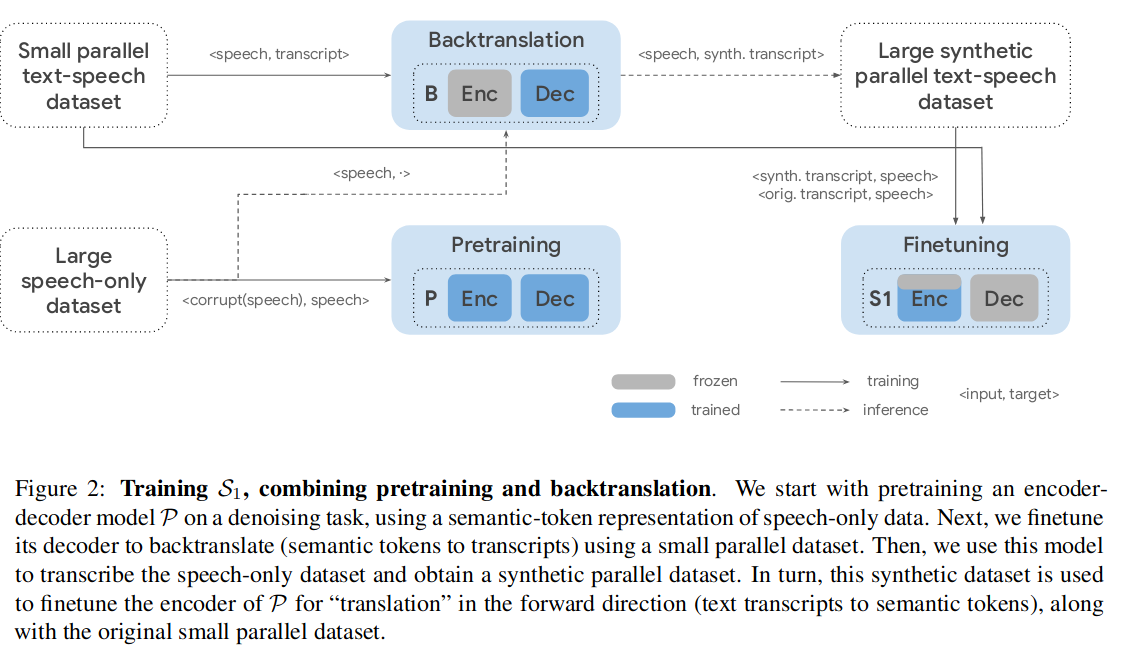
从左下开始看图 -2,首先,利用有限数据的损坏方法(加噪再去噪)来预训练模型 P,生成语义 token 表征音频数据;然后训练回译模块,利用少量的并行数据微调解码器,训练模型 B;利用模型 B 的回译方法以及大量无标签数据生成大量可用于训练的并行数据(右上);最后用所有并行数据精调模型(右下)只精调编码器的下面几层。
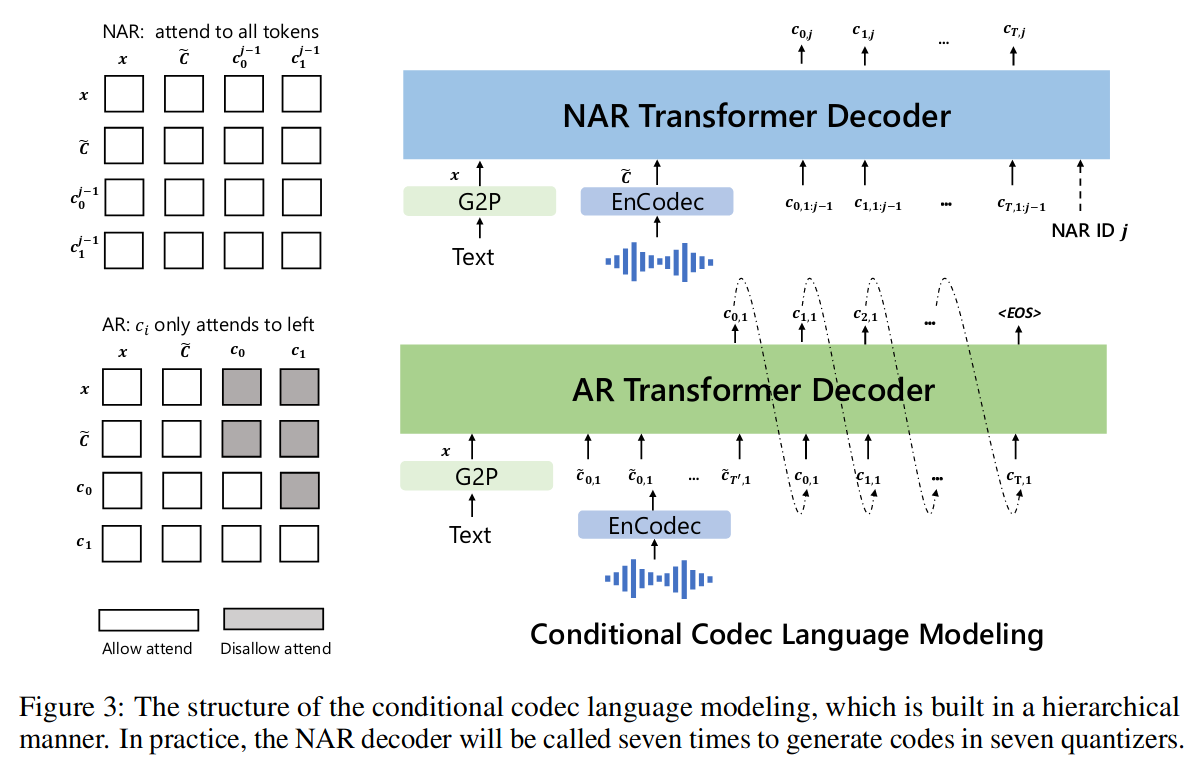
3.3.3 VALL-E
- 时间:2023-01-05
- 出处:Microsoft
- 贡献:用 3s 录音和文本对应的音素生成语音。
- 结构:也是 AudioLM 的延展,比 Spear-TTS 早一些。
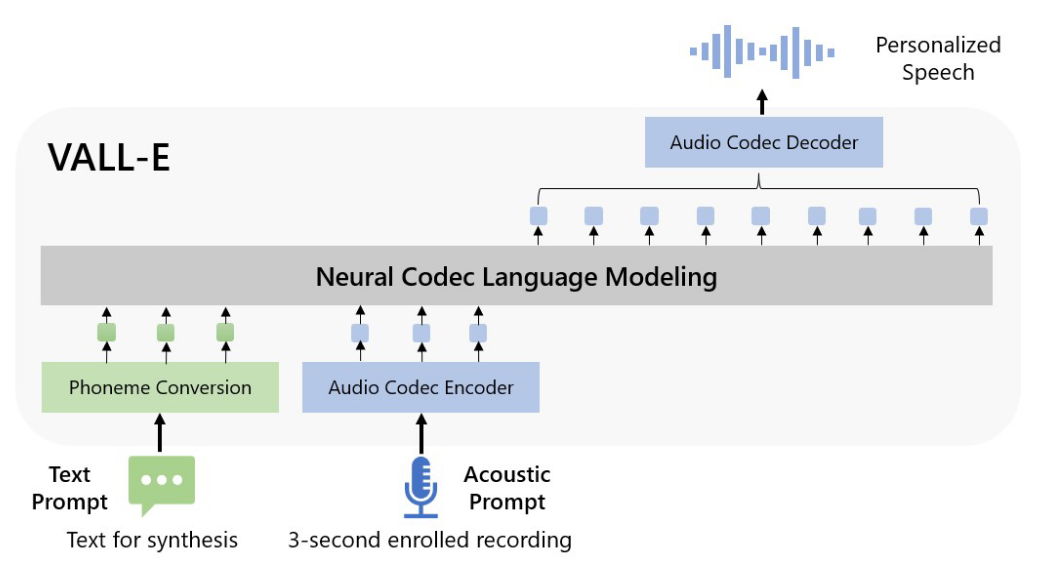
以分层的方式设计了两个条件语言模型,一个用于生成声音 c1(自回归 AR),一个用于精调声音 c2-8(NAR 非自回归)。AR 模型和 NAR 模型的结合在语音质量和推理速度之间提供了良好的折衷。
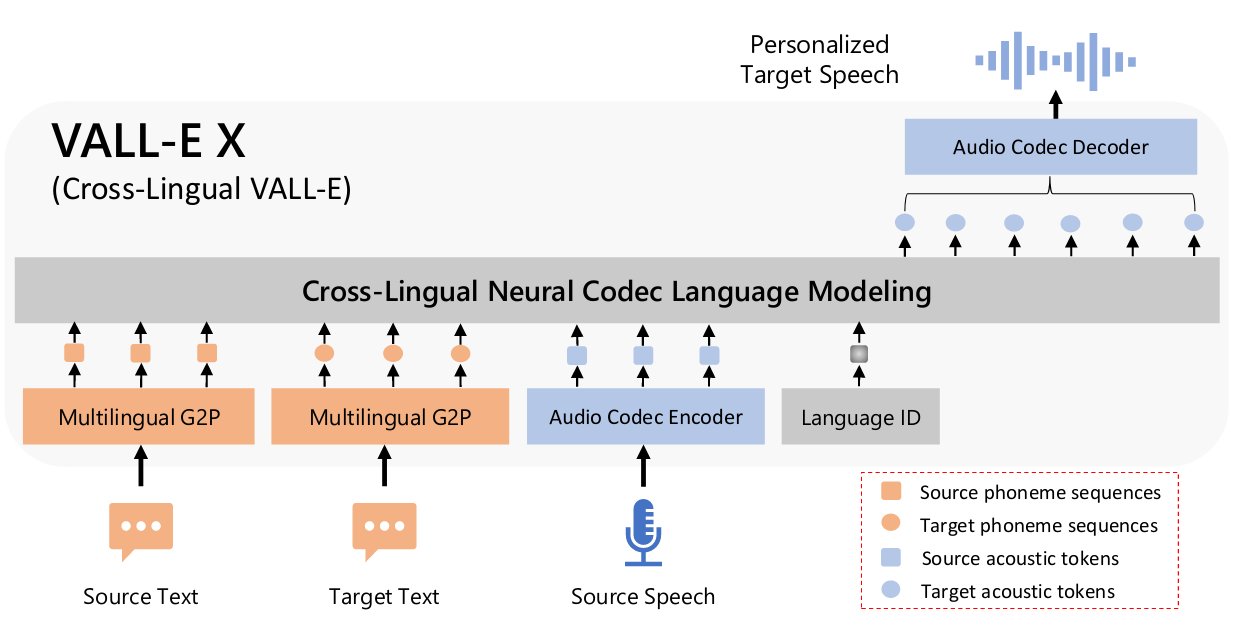
3.3.4 VALLE-X
- 时间:2023-03-07
- 出处:Microsoft
- 贡献:以源语言语音和目标语言文本为提示,预测目标语言语音的声学标记序列,可用于从语音到语音的翻译任务。它可以生成目标语言的高质量语音,同时保留看不见的说话者的声音、情感和声学环境。有效缓解了外国口音问题,可以通过语言 ID 来控制。
- 结构:与 VALL-E 基本一致,但使用多语言训练,并加入了语言 ID。除了模型本身,结合使用 G2P Tool 将文本转换成音素,以及最后使用 Encodec 生成音频数据。
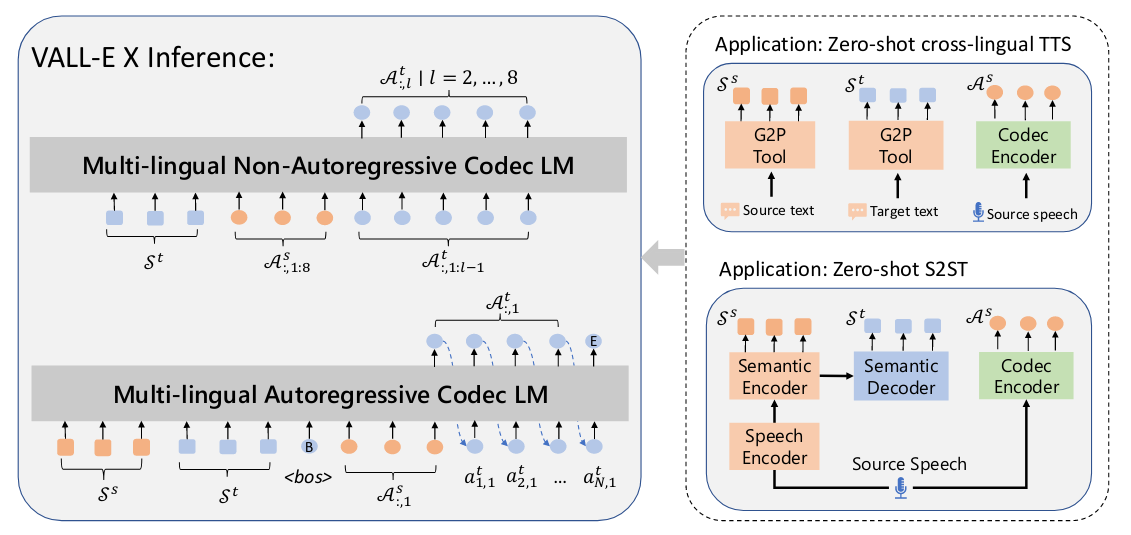
自回归和非自回归模型的输入不同;右侧显示了语音到语音翻译的过程。
给定源语音 Xs,语音识别和翻译模型首先从语义编码器生成源音素 Ss,从语义解码器生成目标音素 St。此外,使用 EnCodec 编码器将 X 压缩为源声学标记 As。然后,将 Ss、St 和 As 连接起来,作为 VALL-E X 的输入,以生成目标语音的声学标记序列。使用 EnCodec 的解码器将生成的声学标记转换为最终的目标语音。
3.3.5 BARK
- 时间:2023-04
- 出处:suno-ai
- 贡献:开包即用的多语言语音合成器,可在本地部署使用。
- 结构:

Bark 通过三个 Transformer 模型,将文本转换为音频。
文本到语义 Token
输入:由 Hugging Face 的 BERT 标记器分词的文本
输出:编码生成音频的语义 Token
语义到粗略 Token
输入:语义 Token
输出:来自 Facebook 的 EnCodec 编解码器的前两个 codebooks 的 Token
粗略到细节 Token
输入:EnCodec 的前两个 codebooks
输出:EnCodec 的 8 个 codebooks