UVR5音频去声器分析
1 读后感
UVR5(Ultimate Vocal Remover 5)是一款音频处理工具,主要用于从混音中分离人声和乐器轨道。它的主要目标是去除人声,保留乐声。然而,使用该工具提取人声可能会遇到一些问题。
其原理基于卷积神经网络(CNN)和自动编码器等模型。
- 音频文件被转换成频谱图,通常是通过短时傅里叶变换(STFT)将时域信号转换成频域表示。
- UVR5 可能使用了一种称为 U-Net 的神经网络架构,它是一种常用于图像分割的模型。这种网络结构适用于音频分离,因为它能够在不同的频率和时间尺度上捕捉到音频的特征。
- 预训练好的模型会接收混合音频的频谱图作为输入,并输出两个频谱图:一个对应人声,另一个对应伴奏。
2 相关论文信息
1 | 英文名称: MULTI-SCALE MULTI-BAND DENSENETS FOR AUDIO SOURCE SEPARATION |
3 论文摘要
- 目标:解决音频源分离问题
- 方法:提出了一种新的网络架构,扩展了密集连接卷积网络(DenseNet),在 DenseNet 之上集成了上采样层、块跳跃连接和频段专用密集块;并利用了长上下文信息。
- 结果:在信失比方面大大优于 SiSEC 2016 竞赛的最新结果,它所需的参数更少,训练时间也更短。
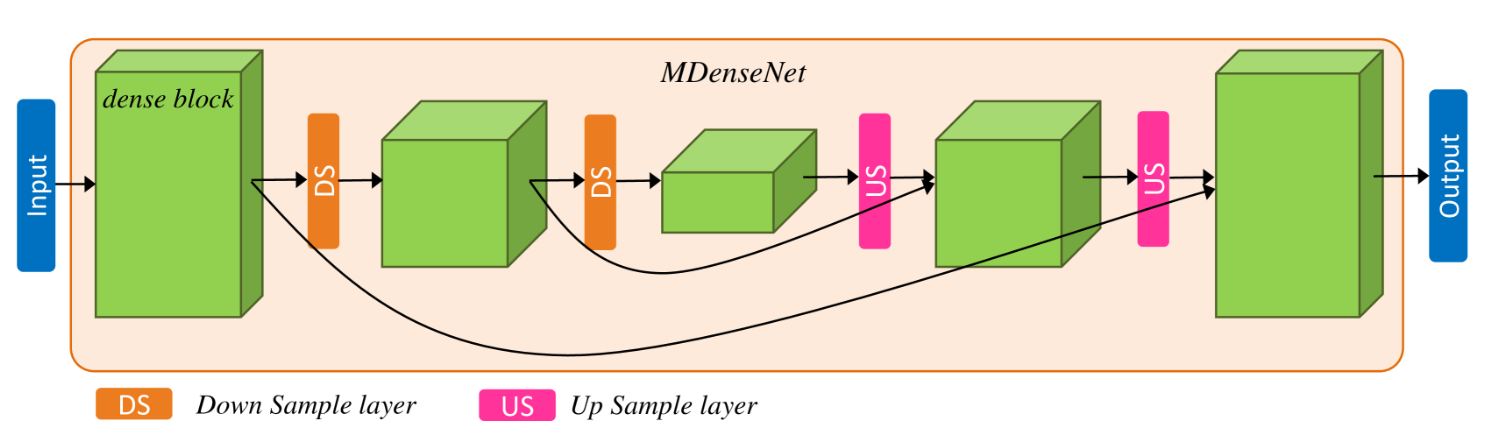
图 2:MDenseNet 架构。多尺度密集块通过下采样层或上采样层或通过块跳跃连接进行连接。图中显示了这种情况 s=3 。
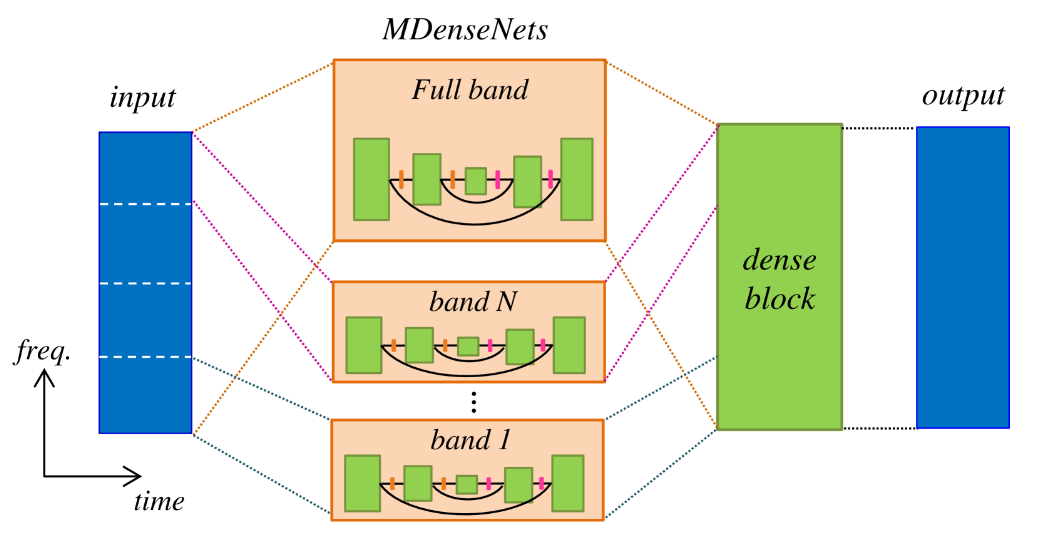
图 3:MMDenseNet 架构。每个频段(包括全频段)专用的 MDenseNet 输出被连接起来,最终的密集块集成了这些频段的特征以创建最终输出。
4 使用感受
- 太惊艳了,让我全身起鸡皮疙瘩。特别是用耳机听时,试用的第一个人声几乎完美无损。
- 声音效果越接近正常,效果就越好。不能使用有明显回声的声音,比如广播剧片头效果。
- 可以很容易去除背景音乐、铃声等有规律的声音,但对自然界的声音处理不好,比如鸟叫。
- 看起来占用了较多内存,但显存占用较少。转换一个 20 多分钟的文件大约需要 2-4 分钟左右,而一两分钟的文件只需要几秒。
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.