TinyLlama: 一个开源的小型语言模型
1 | 英文名称: 'TinyLlama: An Open-Source Small Language Model' |
1 读后感
文中介绍了 TinyLlama 一种开源的轻量级大语言模型。作者发布了所有相关信息,包括的预训练代码、所有中间模型检查点以及数据处理步骤的细节。TinyLlama 可以在移动设备上支持最终用户应用程序,并作为测试语言模型的轻量级平台。
TinyLlama 相对于 Llama2,在架构和算法上都没有太多改进,但有一些微调,旨在测试用更多 token,更小模型的训练结果,以及提交训练效率的方法。
论文正文 5 页左右。
2 摘要:
目标:TinyLlama 是在约 1T tokens 上进行了约 3 轮 (epochs) 的预训练的,大小为 1.1B 的紧凑型语言模型。
方法:基于 Llama 2 的架构和分词器,它利用了开源社区的各种新技术,实现了更好的计算效率。
结论:在一系列下游任务中,明显优于具有相似尺寸的现有开源语言模型。

3 引言
自然语言处理的最新进展在很大程度上是通过扩大语言模型规模来推动的。一些实证研究表明,要训练最优模型,模型的大小和训练数据量应以相同的速度增加。
也有实验证明,当使用更多数据训练时,较小模型训练较长时间的情况下,较小的模型可以匹配甚至优于较大的模型。
文中工作的重点是探索使用非常大量的数据训练具有参数量较小的模型,且开源了 TinyLlama。
4 预训练
4.1 预训练数据
采用自然语言数据和代码数据混合预训练 TinyLlama,从 SlimPajama 获取自然语言数据(1.2 T tokens),从 Starcoderdata 获取代码数据(86 种编程语言,约 250 B token)。采用 Llama 的分词器来处理数据。
将两个语料库结合起来后,总共有大约 950B Token 用于预训练。训练 3 轮 (epochs)。在训练过程中,以自然语言数据和代码数据之间大约 7:3 的比例采样。
4.2 架构
采用与 Llama 2 类似的模型架构

位置嵌入使用 RoPE 旋转位置嵌入;归一化使用 RMSNorm 提高训练效率;激活函数使用 SwiGLU;注意力使用 Grouped-query Attention 分组查询,以减少内存带宽开销并加快推理速度,它可在多个头之间共享键和值表示,而不牺牲太多性能。
4.3 速度优化
完全分片数据并行(FSDP)
在训练期间,集成了 FSDP,以有效地利用多 GPU 和多节点设置,显著提高了训练效率。
Flash Attention
集成了 Flash Attention 2 优化的注意力机制,以提高计算吞吐量。
xFormers
用原始的 SwiGLU 模块替换了 xFormers 中的融合 SwiGLU 模块。以减少内存占用,使 1.1B 模型能在 40GB 的 GPU RAM 训练。
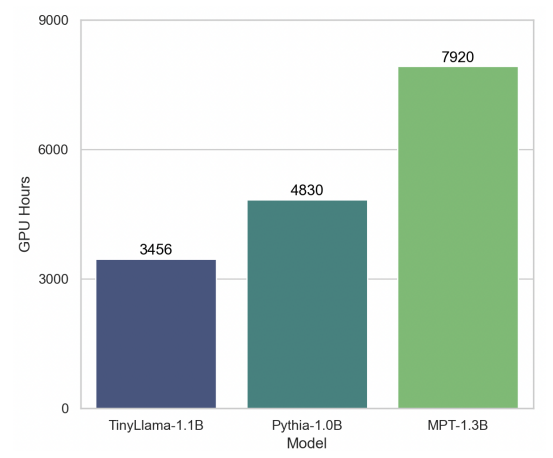
图 1:训练速度比较。
性能分析及与其他型号的比较
将训练吞吐量提高到每个 A100-40G GPU 每秒 24,000 token。与其他模型相比,如图所示,TinyLlama-1.1B 模型只需要 3,456 个 A100 GPU 小时即可训练 300B token,在训练中节省大量时间和资源。
4.4 训练
基于 lit-gpt 构建框架,在预训练阶段采用了自回归语言建模目标,与 Llama 2 的设置一致。文中使用 16 个 A100-40G GPU 预训练了 TinyLlama。
5 结果
在广泛常识推理和解决问题的任务上评估了 TinyLlama,将其与大小相似的模型进行比较。
5.1 常识推理评测
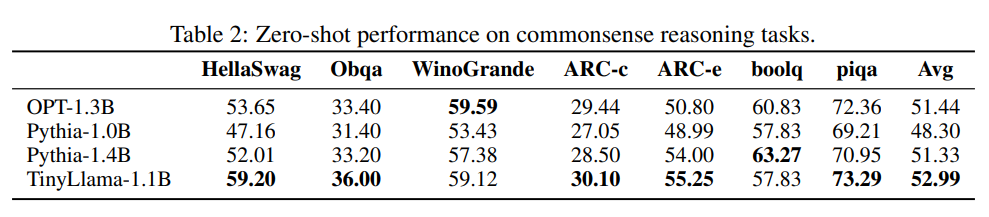
图 2 展示了训练过程中性能的变化:
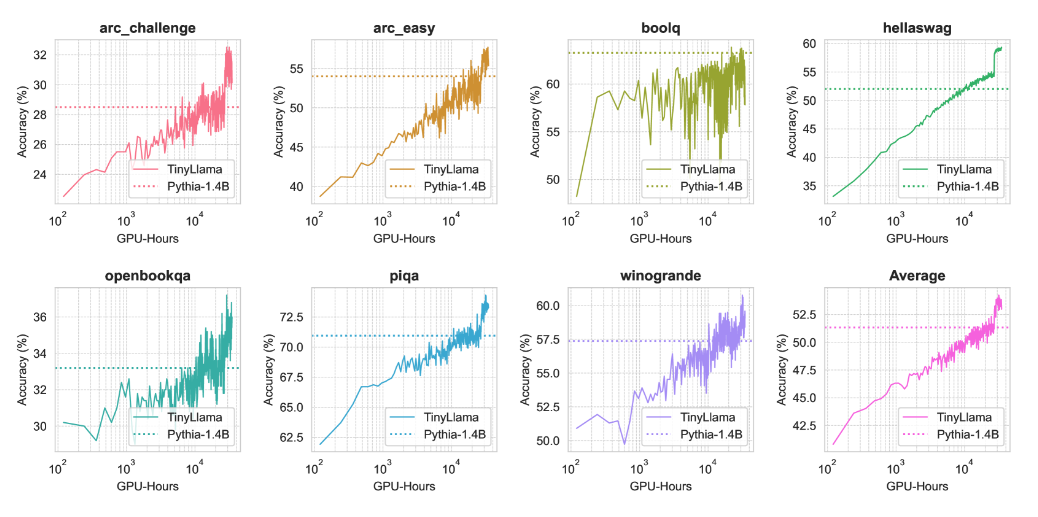
图 2:预训练期间常识推理基准的性能演变,与 Pythia-1.4B 性能比较。
5.2 解决问题评测