论文阅读_ICD编码_MSMN
介绍
英文题目:Code Synonyms Do Matter: Multiple Synonyms Matching Network for Automatic ICD Coding
中文题目:自动 ICD 编码的同义词匹配网络
论文地址:https://export.arxiv.org/pdf/2203.01515.pdf
领域:自然语言处理、生物医疗
发表时间:2022
作者:Zheng Yuan 等,清华大学,阿里巴巴
出处:ACL
代码和数据:https://github.com/GanjinZero/ICD-MSMN
阅读时间:2022.06.14
读后感
通过代入外部资源 UMLS,论文收集了每个编码的同义词,从而弥补了电子病历与 ICD 编码描述中同义不同词的问题。
其算法并没有像之前一些模型那么精巧,但引入外部资源后,效果的确提升不少。
泛读
- 针对问题:ICD 编码中一义多词问题
- 核心方法:
- 提出了多同义词匹配网络 (MSMN)
- 使用LSTM+ 多头注意力
- 将编码的同义词作为 query 以关注描述中的不同短语,从而生成与 ICD 编码相关的表示。
- 使用双仿射的 ICD 编码相似度的文本表示,用于最终分类。
- 泛读后理解程度:
- 半小时看完,半小时整理(这是一篇短文)
方法
ICD 编码同义词
使用 UMLS(一体化医学语言系统) 知识图,对 ICD 编码描述进行扩展,首先,将代码描述 l1 与 UMLS 中的概念唯一标识符 CUIs 对齐;然后从 UMLS 中选择具有相同 CUIs 的英语术语同义词,并通过删除连字符和单词“NOS”来添加额外的同义词。从而对每个 ICD 编码生成 {l2,l3...lM} 文本,下面用 N 表示每个描述包含的单词个数。
编码
使用 LSTM 作为编码器,利用预训练的词向量将词 wi 映射成 xi,使用 d 层的双向 LSTM,将词嵌入作为输入,计算其隐藏层作为表示。
对同义词编码时,使用同样的编码器编码,然后用最大池化获取其表示:
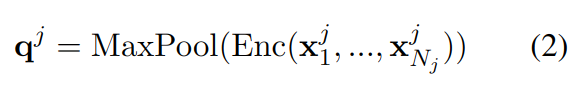
多同义词注意力
受多头注意力的启发,文中使用了多同义词注意力,将隐藏层切分成 M 块(M 头):
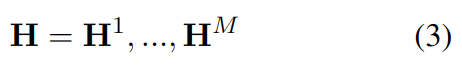
此时,使用编码同义词的表示 qj 来查询 Hj,用 Hj 和 qj 的线性变换来计算注意力得分 a;文本与代码同义词的相关编码可用 Ha 求得。聚合基于编码的文本表示 v,当只需要与一个编码匹配时,使用最大池化计算。
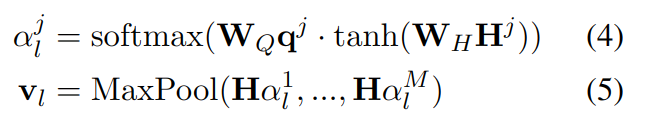
分类器
分类器用于判断文本 S 是否包含 ICD 编码 l,基于前面计算的依赖编码的文本表示 vl和编码的表示 qj,使用双仿射变换来衡量分类的相似性。
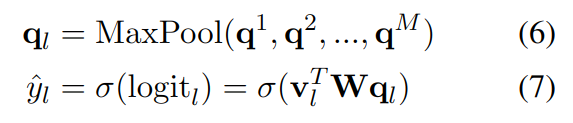
之前很多模型只依赖编码,因此需要训练集中包含每种编码的实例,而这里的 q 是基于编码的文本表示,因此,学习的是文本之间的关系,与具体的代码无关。
训练
用交叉熵来计算预测概率与实际标签的差异: