论文阅读_基于多模态嵌入的产品搜索
1 | 英文名:Que2Engage: Embedding-based Retrieval for Relevant and Engaging Products at Facebook Marketplace |
1 读后感
论文优化了 Facebook Marketplace 中的搜索功能。Facebook Marketplace 是一个电子商务平台,通过用户的个人资料和地理位置信息帮助买卖双方更便捷地联系。
产品搜索是一个多段式操作。搜索检索系统通常侧重于查询与产品之间的语义相关性,而搜索排名则更强调对产品进行排序以提高用户参与度,也就是说:产品字面意思与搜索关键字一致的,但并不一定能提升用户参与度(点击、浏览、购买等行为)。这篇文章旨在弥合检索和排名之间的差距,并涉及对多模态数据(图像/文本)的编码。
作者提出了许多在实际场景中才会被注意到的问题,使用双塔结构模型,在两侧分别使用不同方法优化。本文很好地展示了如何融合多种模型的学习和多种方法的编码。
2 摘要
目标: 提出 Que2Engage,一个旨在优化电子商务搜索系统中检索和排序之间整体搜索体验的嵌入式检索系统。
方法: 采用多模态和多任务方法,将上下文信息融入检索阶段,并在不同业务目标之间取得平衡,通过多任务评估框架进行全面的基线比较和消融研究。
结果: Que2Engage 在部署到 Facebook Marketplace 搜索引擎后,两周的 A/B 测试中显示出用户参与度的显著提升。
1 引言
基于嵌入的搜索(EBR)侧重于学习搜索查询和文档的嵌入表示,以便通过近似近邻(ANN)搜索检索到语义上接近搜索查询的文档。然而,搜索引擎通常是针对多个业务目标进行优化的复杂多阶段系统,因此简单地优化语义相关性可能并不总是能带来最佳结果。需要考虑结合检索和排序两方面。其困难如下:
- 基于对比学习的传统 EBR 建模技术过分强调语义相关性,天真地应用上下文信息可能效果不佳。
- 产品在语义上与查询相关并不意味着它对搜索者有吸引力,同时保持相关性和参与度具有挑战性。
本文介绍了 Que2Engage,它扩展了 Que2Search 以解决上述挑战。采用多模态方法,将上下文信号作为一种独特的模态整合到其 Transformer 融合主干中。该模型采用多任务学习进行训练,将对比学习与排名器式训练相结合,不仅可以检索语义相关的产品,还可以像重新排名模型一样提升更具吸引力的产品。
2 模型
框架设计为双塔神经网络,由查询塔和文档塔组成,分别用于学习搜索查询和电子商务产品的嵌入表示。产品的多模态和上下文信息通过转换器融合方法构建文档塔,并通过多任务学习进行训练。
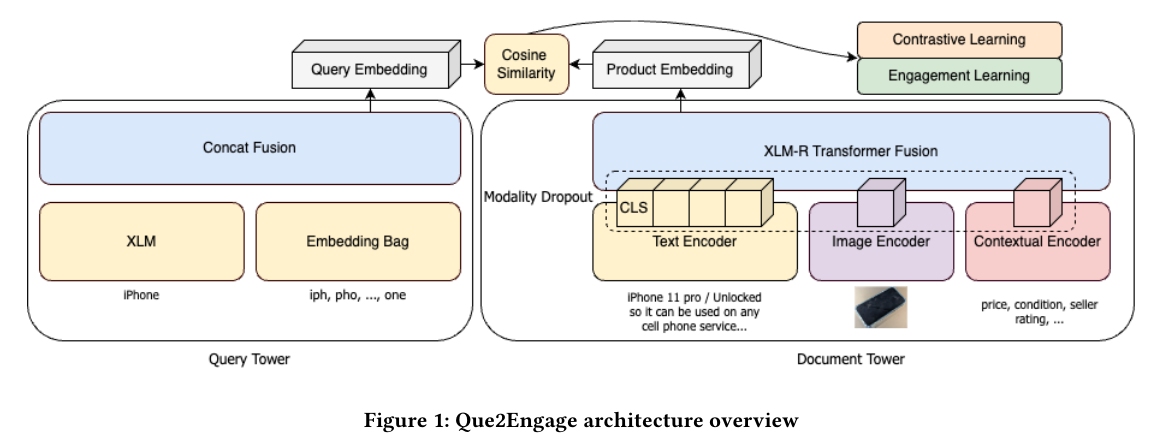
2.1 模型架构
2.1.1 查询塔
采用一种多粒度的搜索查询表示方法,包括原始查询文本和查询的字符三元组(Trigrams,三个字符为一组的基于统计的方法)。原始查询文本通过一个两层的 XLM 编码器进行编码,而字符三元组则使用 EmbeddingBag 编码器进行处理。与之前的方法不同,使用了串联这两种表示方式,而不是通过注意力机制融合它们,随后将结果输入到最终的 MLP 层。
2.1.2 背景信息作为一种模态
在多模态框架中,上下文信息被视为一种独特的模态。对于候选产品列表,使用文档塔中的基于 MLP 的编码器来编码其上下文信息,例如价格、类别和创建时间。数值特征表示为单个神经元,分类特征使用单热编码表示。所有上下文要素都连接起来,然后送到 BatchNorm 层,再传递到最终的 MLP。这确保了固定的数值量度和固定的输出长度。
2.1.3 多模态融合
借用了在 transformer-fusion 架构中使用的方法,将文本令牌(包括产品标题和描述)、图像令牌和上下文令牌串联后,输入到多模态融合编码器中。文本编码器和多模态融合编码器是从多语言模型 XLM-R 的 6 层初始化的。文本编码器继承了前 K 层,多模态融合模型继承了剩余的 M 层。在多模态融合编码器的最后一层,提取标记的隐藏输出,并将其投影到所需维度,作为最终的文档嵌入。
2.1.4 模态 dropout
为了确保模型不会过度依赖单一模态,并且在推理过程中能够处理缺失的信息,引入了模态丢弃机制。该机制随机屏蔽了上下文编码器、图像编码器和文本编码器的输出。
2.1.5 学习图像表示
探索了两种图像编码器变体,以从产品图像中捕获视觉信息。测试了 GrokNet 模型和 CommerceMM 模型,结果显示微调后的 CommerceMM 模型表现更佳。
2.2 多任务训练
2.2.1 对比学习
采用基于批量负采样的约束性学习方法,其中正样本为用户参与的“查询”,这些查询来自去标识化和聚合后的搜索日志中抽取的产品对。负样本通过在 mini-batch 中随机组合查询和正样本中的产品生成。
2.2.2 学习情境信息
上述负采样无法充分学习用户参与度的语境信息。例如,产品价格这样的因素是识别相关产品中引人注目的关键(如价格不合理)。因此,作者提出了一种辅助训练任务,直接优化模型以找出在相关产品中引人注目的产品。具体来说,我们将<查询,产品>对中的未获得搜索者参与的样本作为难负例加入到训练集中。
3 离线实验
从 Facebook Marketplace 的搜索日志中,收集了 1.5 亿次查询与产品的匹配记录。其中,7500 万次记录作为正面样本,接收了下游互动;其余 7500 万次记录作为负面样本,没有接收到互动。为了进行离线评估,收集了 26k 条人工评定数据,用于相关性评估。这些人工评分数据集是通过让评分者决定结果是否与查询相关来生成的。
所有模型均使用 PyTorch 多模态框架在 Nvidia A100 GPU 上开发。
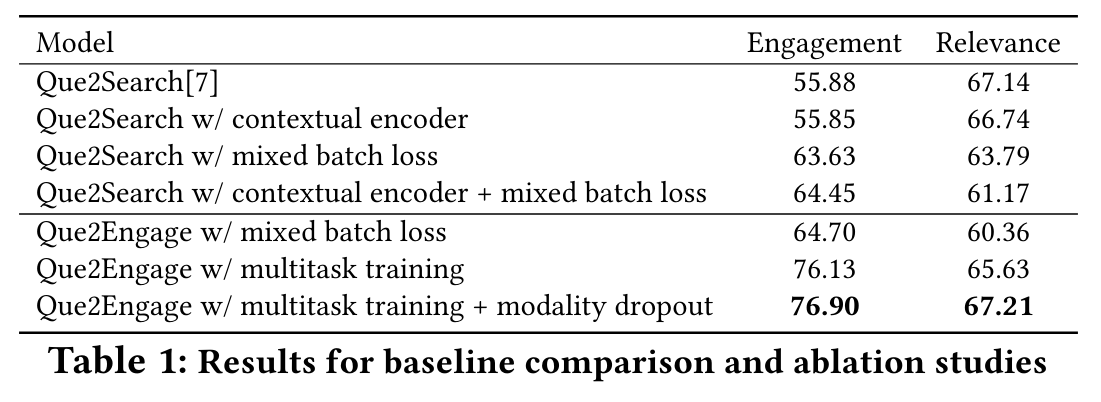
消融实验结果如下,其中选择 Que2Search 问题作为基线模型。Relevance(相关性)评价的是查询与产品的相似度,engagement(参与度:点击、浏览、购买等行为)评价的是排序任务中的表现。
4 在线实验
在 Facebook Marketplace Search 上部署了 Que2Engage,作为传统基于词汇的搜索检索的并行检索源。将 Que2Engage 与 Que2Search 进行了比较。为期两周的在线 A/B 测试表明,Que2Engage 将在线搜索者的参与度提高了 4.5%,同时保持 NDCG 中立。这与我们的离线多任务评估结果一致。