论文阅读_中文生物医学语言理解评价CBLUE
介绍
英文题目:CBLUE: A Chinese Biomedical Language Understanding Evaluation
中文题目:CBLUE:中文生物医学语言理解评价基准
论文地址:https://arxiv.org/pdf/2106.08087.pdf
领域:自然语言处理,知识图谱
发表时间:2021 年
作者:Ningyu Zhang,医渡云、平安医疗科技、阿里夸克、鹏城实验室、北京大学、哈尔滨工业大学 (深圳)、同济大学、郑州大学等共同协办
出处:ACL(自然语言处理顶级会议)
被引量:3
数据:https://tianchi.aliyun.com/dataset/dataDetail?dataId=95414 (需要提交申请)
代码:https://github.com/CBLUEbenchmark/CBLUE
阅读时间:2022.05.09
读后感
训练和评测数据非常全面,还可以在天池打榜。
介绍
之前生物医学方面数据以英文为主,本文收集了真实世界的生物医学数据,提出了第一个中文生物医学语言理解评估标准 CBLUE。其内容覆盖命名实体识别,知识抽取,诊断标准化,句子分类,以及对在线辅助医疗系统的评测。并评测了 11 个预训练的中文模型,对比了模型与人类水平的差异。
相关工作
自然语言评测数据从 GLUE 开始;SuperGLUE 进一步提出更难的任务以及排行榜;另外,还有 DecaNLP 问答评测,以及 SentEval 评测固定大小的句子嵌入。CLUE 是用于评测中文 NLP 的数据集,它包含 9 项任务。文中提出的医学评测 CBLUE 与 CLUE 对比如下:

在生物医疗领域的数据集有评测问答的 PubMedQA,评测阅读理解的的 BioRead。与一般语料不同的是,生物医学语料库的标注需要专家介入,费时费力,且大多基于英文,泛化到其它语言有难度。
CBLUE 概览
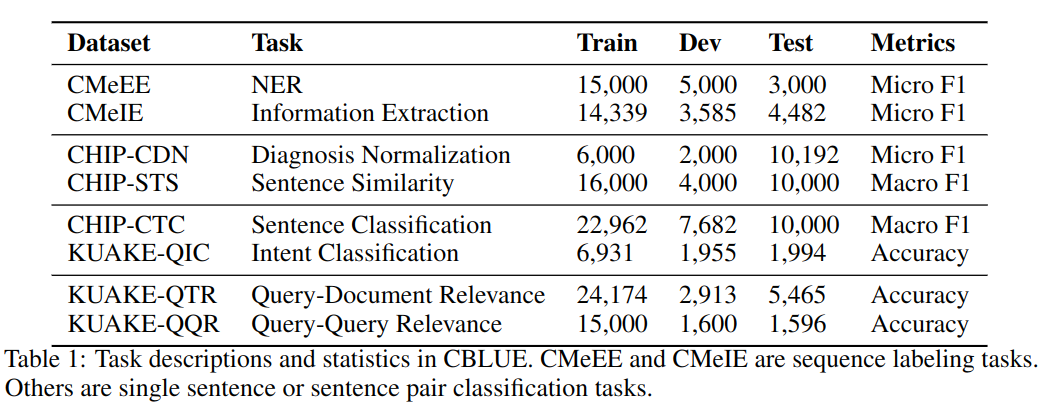
任务
CBLUE 共包含 8 个任务
CMeEE
中文医疗命名实体识别,数据起源于 CHIP 2020(中国健康信息处理会议)。通过从句子里提取实体,归类到九个类别:疾病、临床表现、药物、医疗设备、医疗程序、身体、体检、微生物和科室。
CMeIE
中文医疗信息抽取,数据起源于 CHIP 2020。目标是在遵循约束的句子中识别实体和关系。数据包含 53 种关系,其中 10 个同义子关系,43 个其他子关系。
CHIP-CDN
CHIP 临床诊断规范化,将医生书写的诊断匹配到 ICD-10 标准化。
CHIP-CTC
CHIP 临床试验分类,用于评价受试者是否符合临床试验,共定义了 44 个类别。
CHIP-STS
CHIP 文本语义相似度,主要用于中医疾病问答数据,在病种间迁移学习。它的训练集和数据集针对不同疾病,模型用于评价两个句子的相似度。
KUAKE-QIC
KUAKE(阿里夸克)问询意图分类任务,包含 11 种意图:诊断、病因分析、治疗计划、医疗建议、检测结果分析、疾病描述、后果预测、预防措施、预期效果、治疗费用。
KUAKE-QTR
KUAKE 查询标题相关性任务,给出一个查询,目的是找到相关的标题。
KUAKE-QQR
KUAKE 查询相关性,计算两个查询的相关性,类似 QTR 任务,该任务应用于搜索引擎。
数据总结
功能分类
- 医学信息抽取
- 医疗术语标准化
- 医学文本分类
- 句子语义匹配
- 对话的理解和生成
数据来源
- CHIP 中国健康信息处理会议
- KUAKE 阿里夸克
- IMCS21 复旦大学
- MedDG 中山大学&腾讯天衍实验室
数据收集
数据源如下:
- 数据临床实验:从 ChiCTR(中国临床试验注册中心)获取,供 CHIP-CTC 任务使用。
- 电子健康记录:获取了几家三甲医院的病历最终诊断,从不同的医疗科室抽取了诊断项,构建 CHIP-CDN 数据集,诊断项目是从常见医学同义词词典未涵盖的项目中随机抽样的。
- 医学论坛和教材:新冠流行后,在线医疗咨询增多,用线上问题生成 CHIP-STS 数据集时发现,很多是投诉。为了保证语料库的权威性和实用性,还选择了儿科学、临床儿科学和临床实践 6 的医学教材。主要用于构建 CMeIE 和 CMeEE 数据。
- 从搜索引擎日志中收集:利用夸克搜索引擎,先过滤出医学标签数据,所有的文档分为高、中、尾三类,然后对数据进行统一采样,以保证多样性。供 KUAKE-x 使用。
标注
每个样本由三到五名领域专家进行注释,并采用投票最多的注释来估计人类的表现。去掉了训练阶段低水平的人,以保持严格和较高的标准,随机审查每人至少 10 个样本,作为评价。最终,使用 Kappa 分数计算注释者的一致性,发现六个注释中有五个显示出几乎完美的一致性 (κ=0.9)。
特点
- 匿名化同时保证效果
- 采样符合真实世界分布:保持长尾分布,支持标签粗细粒度的层次。
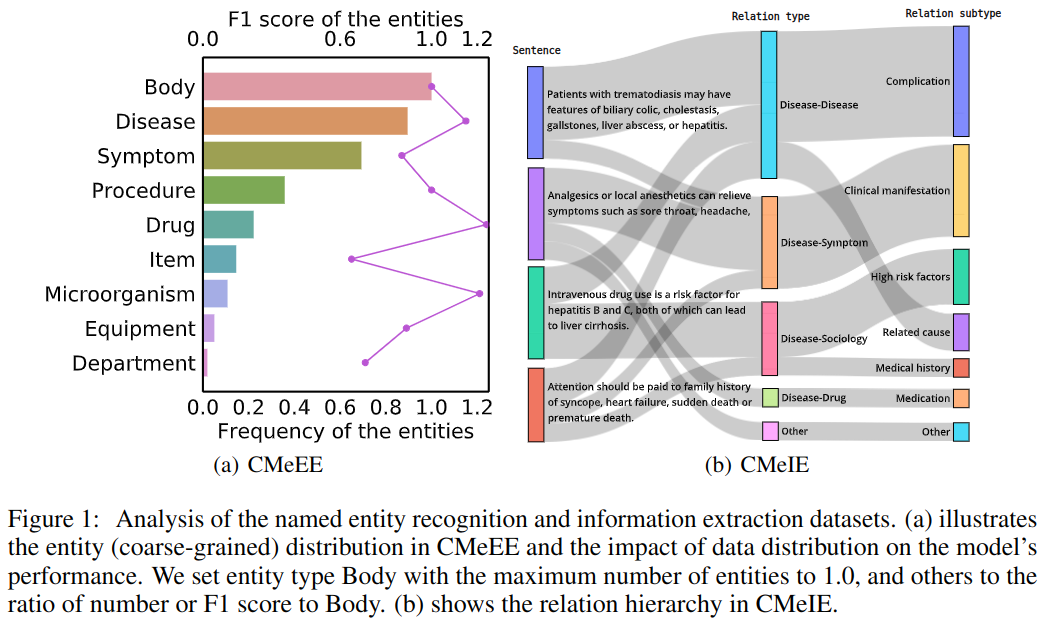
- 多样化的任务设置
排行榜
参与者提交对测试集的预测结果,评价系统给出得分。且阿里云平台提供 60 小时 GPU 训练时间,以训练模型。
维护
CBLUE 1.0 在 2021 年 4 月 1 日发布,开始支持 8 项任务,持续更新中。
目前已更新致 CBLUE 2.0,共建单位新增了“复旦大学”、“腾讯天衍实验室”和“中山大学”,任务种类增加到 15 个。
新增任务如下:
- CHIP-CDEE:临床发现事件抽取
- CHIP-MDCFNPC:医疗对话临床发现阴阳性判别
- IMCS21:智能对话诊疗数据集(含四个子任务)
- IMCS-NER 命名实体识别
- IMCS-SR 症状识别
- IMCS-MRG 医疗报告生成
- IMCS-IR 意图识别
- IMCS-NER 命名实体识别
- MedDG:蕴含实体的中文医疗对话生成
实验
基准结果
使用多个预训练中文模型评测,对每个任务外加一个层来精调预测训练模型。结果如下:
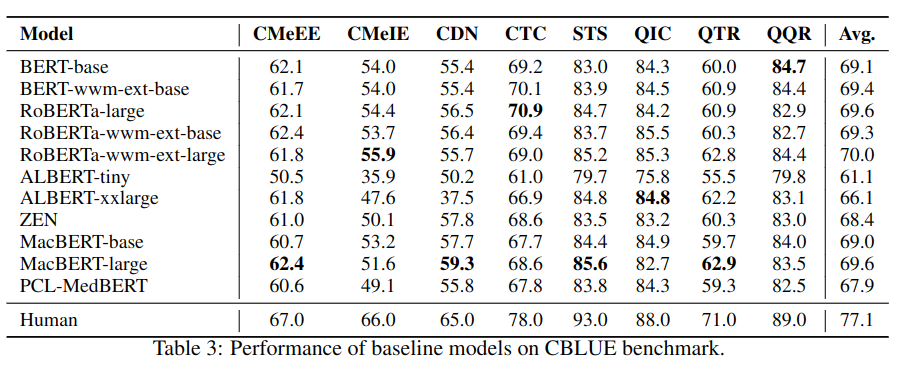
效果分析:大的模型效果更好;使用全词并不是在所有任务中表现都好;小的模型 Albert-TINY 在有些领域中表现也不是太差(CDN、STS、QTR 和 QQR);用医疗数据训练出来的模型 PCL-MedBERT 效果没有预想中那么好。
人的表现
业余人士经过训练后标注效果如下,和机器相比,人标注效果更好。
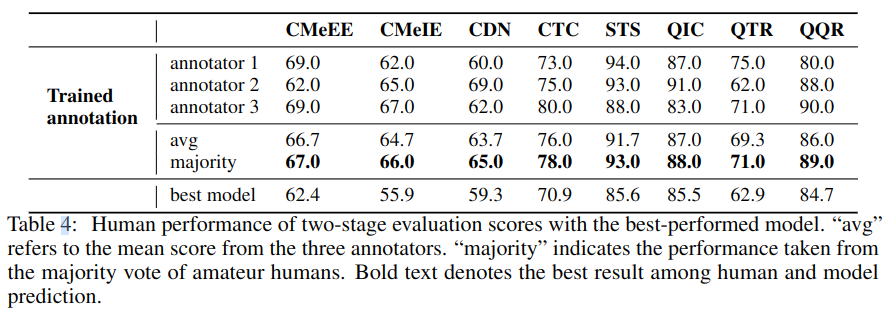
个案分析
错误原因分析如下:
