7_1_强化学习_ChatGPT为什么使用强化学习
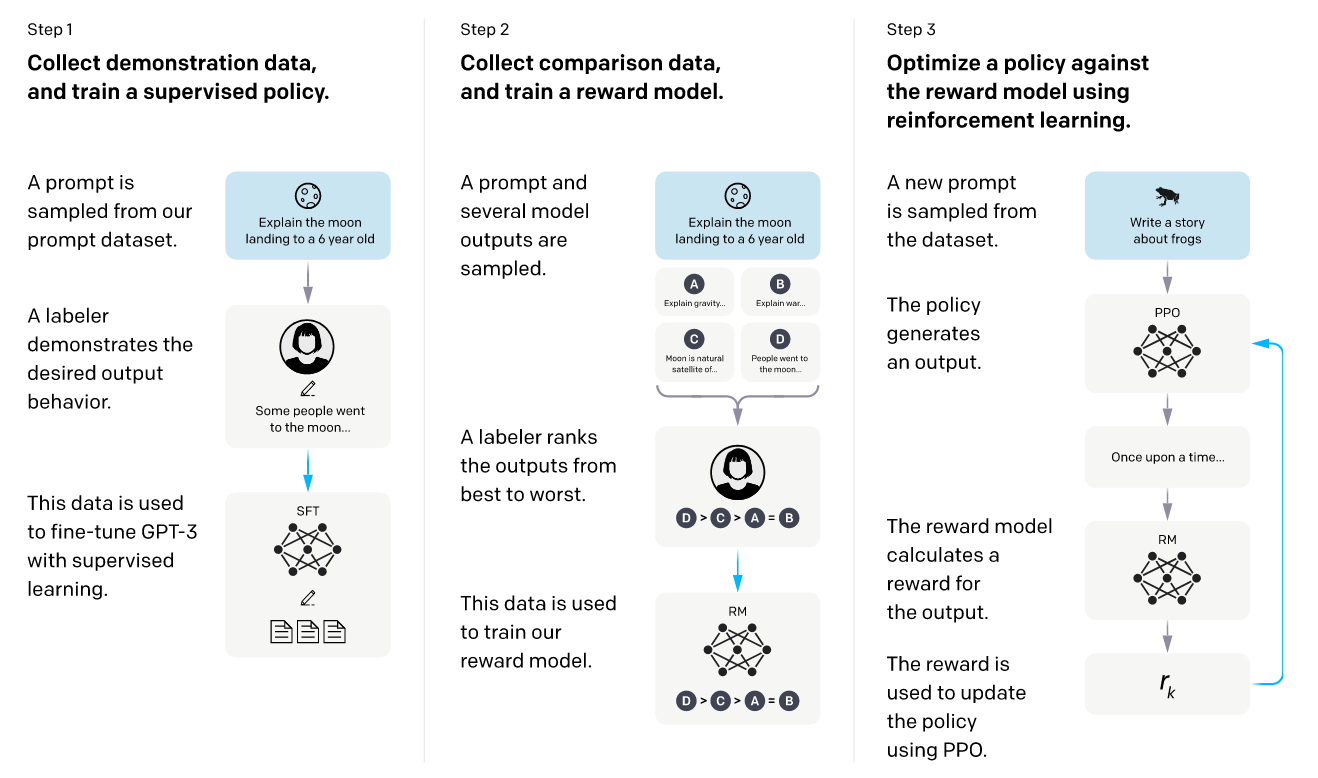
最近出现很多 ChatGPT 相关论文,但基本都是讨论其使用场景和伦理问题,至于其原理,ChatGPT 在其 主页上 介绍,它使用来自人类反馈的强化学习训练模型,方法与 InstructGPT 相同,只在数据收集上有细微的差别。
那么,InstructGPT 和 ChatGPT 为什么使用强化学习呢?先看个示例:

先不论答案是否正确,回答依赖之前的对话,且不仅是前一句。
强化学习用于解决具有马尔可夫性的问题,马尔可夫性是指每个状态仅依赖前一个状态,而这种链式的关系,又使历史信息被传递到了未来。
强化学习使用的场景是 马尔可夫决策过程,包含以下核心点:
- 随机过程:人机聊天你一句我一句
- 马尔可夫性:回答依赖问题
- 奖利:问题可能有多种答案,答案没有绝对的对错,但提问者会对某个答案更满意
- 行为:每一次决定如何回答都对后续对话走向产生影响
可以看到聊天的场景是一个马尔可夫决策过程。
进而产生了另一个问题:模型需要大量数据训练,如果用户问个问题,出三个答案,让用户选一个,收集以用于训练模型。这肯定是不够友好,软件在初期效果不佳时也不会有人去用。且有些用户的回答还可能误导模型。
于是,需模仿真实的使用场景,根据用户对答案的偏好,生成奖励值,以进一步训练强化学习模型。即:对场景建模,这也是强化学习的重要部分:基于模型的强化学习(model-based reinforcement learning)。
结合 GPT 自然语言模型(第一列),奖励模型(第二列),代入强化学习算法(第三列),让模型训练和更新筛选答案的策略。简言之,自然语言模型针对人提出的问题生成 N 种答案,由强化学习根据当前情况,选择其中最符合用户偏好的答案。
用什么样的文本训练它,它就会生成什么样的文字,从互联网上抓取的数据,学到的也都是大多数声音。而通过人标注数据的引导,可以影响和改变它的行为,比如:在第一列可通过喂给模型更多更高质量的数据,让它在细分领域更具专业性;而通过人工标注数据训练第二列的奖励模型,可以约束和引导它的行为。当然,日后还会发展出更好的结构。
至少,到目前为止,它们只是自然语言生成工具,具有一定的语言能力,可以照猫画虎地根据上文生成下文(一种或多种答案),再用强化学习方法,根据当前情境,从答案中选出相对靠谱的显示出来。所以说,不能指忘它是全知,具有上帝视角回答那些专家都不确定的问题。