论文阅读_ICD编码_BERT
英文题目:BERT-based Ranking for Biomedical Entity Normalization
中文题目:基于 bert 的生物医学实体标准化排序
论文地址:https://arxiv.org/pdf/1908.03548
领域:自然语言处理,生物医学,实体标准化
发表时间:2019
作者:Zongcheng Ji, 德克萨斯大学
被引量:6
阅读时间:22.06.20
读后感
中规中矩的方法,评测了各个预训练模型的差异。
介绍
BERT 是常用的自然语言处理深度学习模型, BoiBERT 和 ClinicalBERT 是针对医疗领域预训练的模型,文中提出的架构用于将上述模型通过微调解决医疗实体规范化问题.
实体规范化 Entity linking,主要面临以下挑战:
- 歧义问题:同一实体可能与多个概念相连
- 变体问题:同一概念可能与不同的实体相连
- 缺失问题:实体不与知识库中的任务概念相连
(这里指的概念是规范化后的文本)
在医疗领域主要任务是对实体的规范化和编码,变体问题是医疗领域的主要问题。
方法
已知文档的句子中的有实体 m,以及包含很多概念的知识知识库 KB,任务是将实体 m 连接到 KB 中的概念 c,如果找不到,则认为不可达 unlinkable。
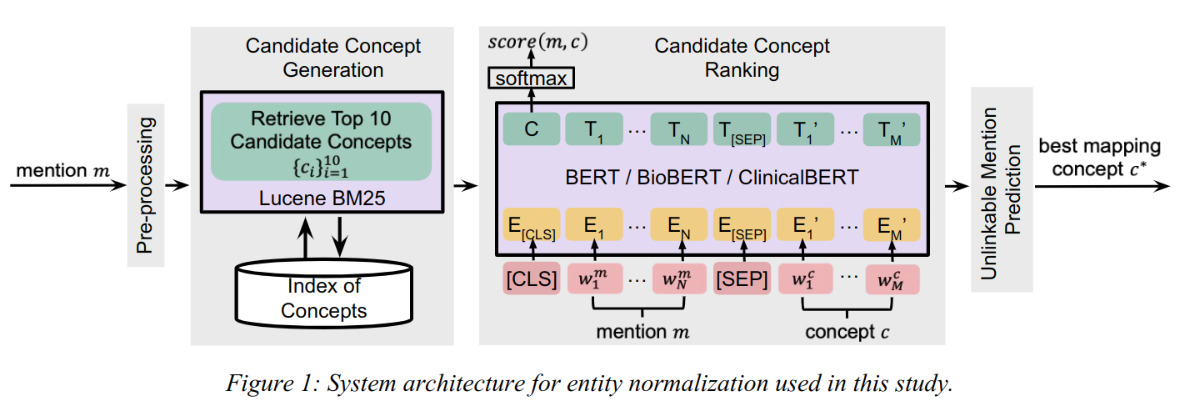
图 -1 展示了文中方法的结构,包含四个模块:预处理、创建候选项、候选项排序、预测不可达。
预处理
对于 m 和 c 都进行如下操作:
- 拼写纠错
- 缩写转换
- 处理数字符号
- 其它预处理:使用CLAMP28工具包,处理标点,大小写等。
生成候选概念
利用传统的 BM25 模型。首先,提取所有概念 c 和训练集中的 m 用于训练模型,对于 m,选择模型推荐的前 10 个近似项 c 作为候选概念。
候选概念排序
使用预训练的 BERT/BioBERT/ClinicalBERT 模型,将排序任务转换成句子对的分类任务。对于每个 m 与对应的 c,构建 [CLS] m [SEP] c 输入模型,精调模型参数。当 m 中包含概念 c 时,其类别为 1,否则为 0。
预测不可达
m 中的实体可能找不到对应概念 c,因此,需要预测不可达的情况。如果 BM25 不能返回候选项,则认为不可达。另外,设定一个阈值,如果相似度得分小于阈值,则认为不可达。
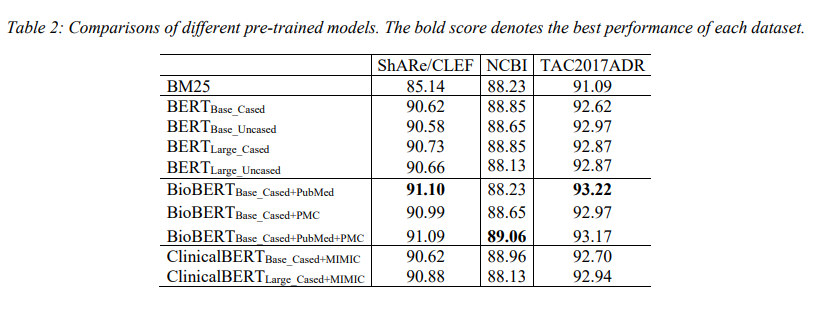
实验结果