论文阅读_字典提升基于BERT的NER
用字典提升基于 BERT 的中文标注效果
论文题目:Lexicon Enhanced Chinese Sequence Labeling Using BERT Adapter
论文地址:https://arxiv.org/abs/2105.07148
读后感
论文提出将字典融入 BERT 网络层记作字典加强 BERT(Lexicon Enhanced BERT,LEBERT),用于提升中文标注效果。新模型在命名实体识别、分词、成份标注实验中均达到了目前最佳水平。
简介
这是一篇自表于 2021 ACL(NLP 顶会)的论文。
由于存在分词(CWS)问题,中文面临更大的挑战,对多数任务,以字为单位比以词为单位效果更好。
目前大多优化方法都是修改上层(网络末端),而未修改核心网络。文中提出的方法利用字典得到更多可能的分词,动态计算最佳分词方法,并修改了网络的 Transformers 层,如图 -1 中的右图所示:
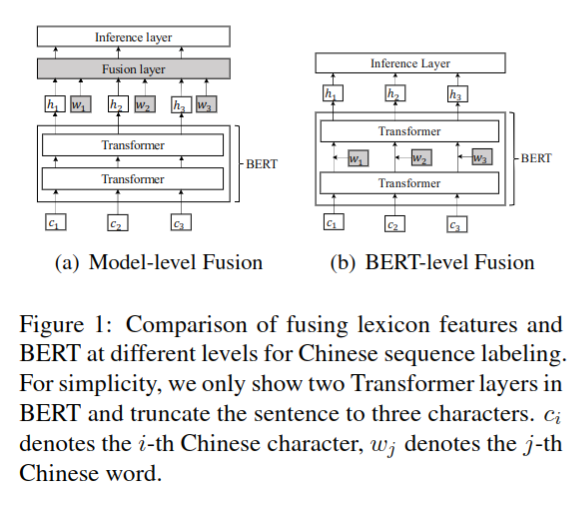
模型
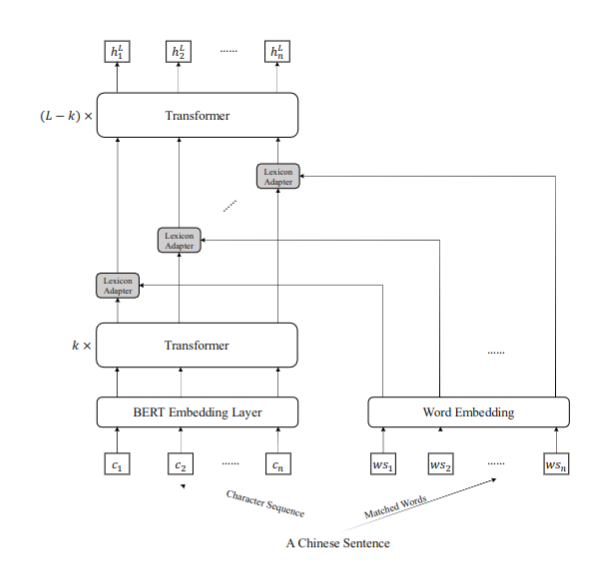
模型的核心结构如图 -2 所示,相对于 BERT,LEBERT 有两个明显差别:(1)输入变成了字符特征 + 字典特征(2)字典适配层在 Transformer 层之间。
字词配对
文中方法将基础的字符序列扩展成字符 + 词对序列,设句 S 由字符 c 组成:Sc={c1,c2,c3,...,cn},在字典 D 中找到在句中包含字符 c 所有可能的词 ws,如图 -3 所示:
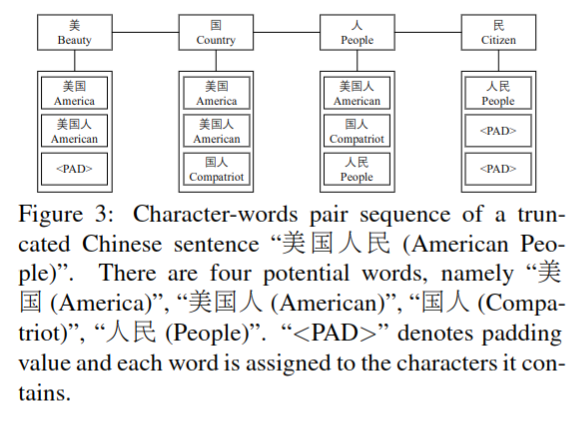
最终生成序列:
s_cw={(c1,ws1),(c2,ws2),...(cn,wsn)}
字典适配
将字符和词信息融入 BERT 网络的字典适配层,方法如图 -4 所示:
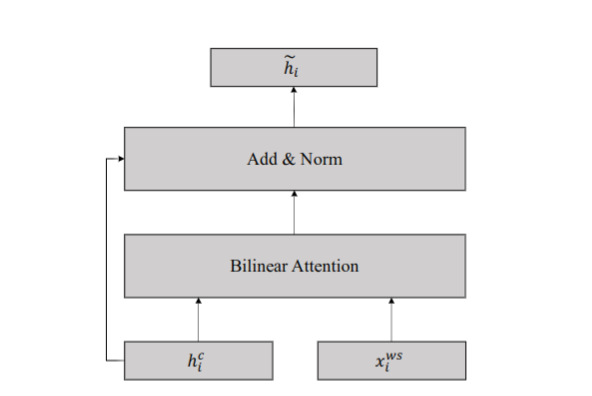
字典适配层有两个输入:字符和词对,即上图中的 h 和 x,其中 h 是前一个 transformer 层输出的字符向量,x 是 m 个可能包含该字符的词组成的词嵌入,其中 j 是 m 中的第 j 个词:
\[ x_{ij}^w=e^w(w_{i,j}) \]
其中 e 是预训练得到的词向量映射表。
为了对齐长短不一的序列,对词向量进行非线性变换如下:
\[ v_{ij}^w=W_2(tanh(W_1x_{ij}^w+b_1))+b_2 \]
其中 W1 是大小为 dc-dw 的矩阵,W2 是大小 dc-dc 的矩阵,b1 和 b2 是偏移,dw 是词向量的维度,c 是隐藏层的维度。
由图 -3 可知,一个字可能对应多个词,对于不同的任务,最匹配的词可能并不相同。
具体算法是使用 vi 表示第 i 个字符对应的所有词表,m 是该字符可能对应的词个数,计算注意力 attention 如下:
\[ a_i=softmax(h_i^cW_{attn}V_i^T) \]
其中 W 是注意力权重矩阵。
然后对每个词乘其权重加和,得到位置 i 对应的词表示:
\[ z_i^w=\sum_{j=1}^m a_{ij}v_{ij}^w \]
最终,将词典信息与字符的向量相加,得到了该位置的新向量:
\[ \widetilde{h}_j=h_i^c+z_i^w \]
处理后的数据再送入 dropout 层和归一化层继续处理。
用字典加强 BERT
将字符输入词嵌入层,加入 token, segment 和 position 信息,然后将该层输出的词嵌入输入 Transformer 层:
\[ G=LN(H^{l-1}+HMAttn(H^{l-1}))\]\[H^l=LN(G+FFN(G) \]
输出的 \(H^l\) 是第 l 个隐藏层的输出,LN 是归一化层,HMAttn 是多头注意力机制,FFN 是两个前馈网络层,使用 ReLU 作为激活函数。
在 k-th 和 (k+1)-th Transformer 之间加入字典信息
\[ \widetilde{h}_i^k=LA(h_i^k,x_i^{ws}) \] ### 训练和解码
考虑到标签的前后关系,使用 CRF 层来预测最终的标签,将最后一个隐藏层 h 的输出作为输入,计算输出层 O:
\[ O=W_oH^L+b_o \]
然后将输出层代入 CRF 模型,计算标签 y 的概率 p。
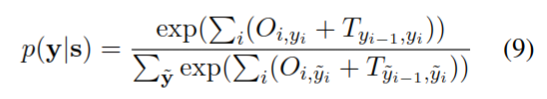
训练时给出句子 S 和标签 Y,计算全句的负对数似然作为误差。
\[ L=-\sum_jlog(p(y|s)) \]
解码时,使用维特比算法计算得分最高的序列。
实验
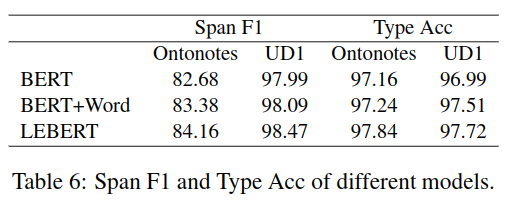
论文针对命名实体识别 NER,分词 CWS、位置 POS 标注进行了实验,实验数据如表 -1 所示(中文 NLP 常用实验数据)。
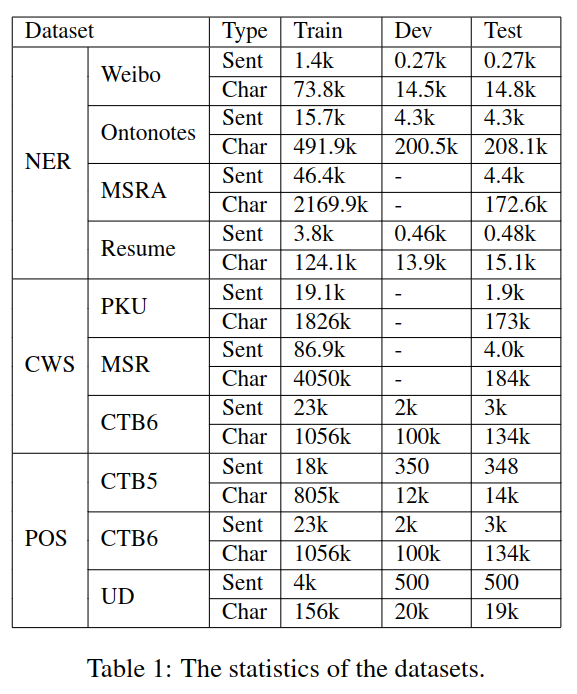
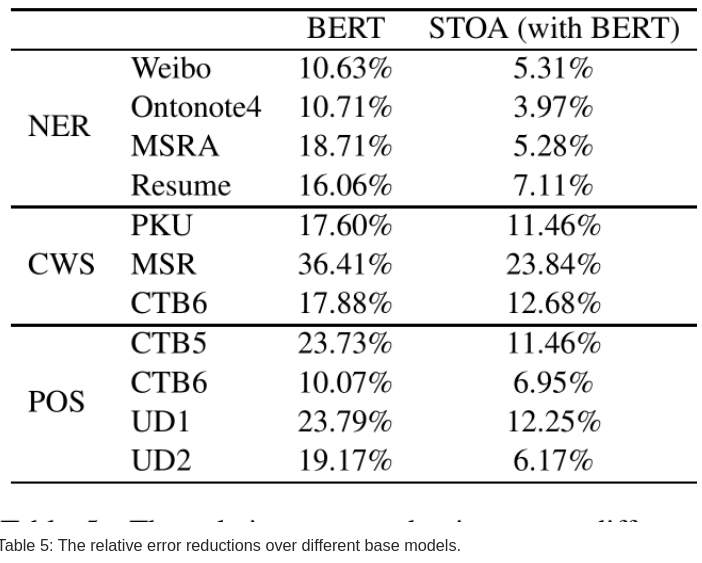
图 -5 展示了相对于 BERT 和基于 BERT 的最新模型,文中模型误差的减少情况。
除了与其它模型比较之外,论文还比较了 LEBERT 方法与在组装模型的 Bert+Word 方法的差异。