论文阅读_I-JEPA_从图像中进行自监督学习的联合嵌入预测架构
1 | 英文名: Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture |
摘要
目标: 通过无手工设计的数据增强方法学习具有高度语义性的,并且不需要在下游任务上进行大量微调的图像表示。
方法: 提出了图像基础的联合嵌入预测架构(I-JEPA),一种自监督学习的非生成性方法,核心思想是从单个上下文块预测同一图像中不同目标块的表示。
结果: 当与 Vision Transformers 结合使用时,I-JEPA 表现出高度可扩展性,能够在不到 72 小时内在 ImageNet 上使用 16 个 A100 GPU 训练 ViT-Huge/14,并在从线性分类到对象计数和深度预测等各种任务中实现了强大的下游性能。(比使用 MAE 预训练的 ViT-H/14 效率高 10 倍以上。)
目标:通过无手工设计的数据增强方法,学习出具有高度语义性,无需在下游任务上进行大量微调的图像表示。
方法:提出了一种名为图像基础的联合嵌入预测架构(I-JEPA)的自监督学习方法。其核心思想是通过从单个上下文块预测同一图像中不同目标块的表示,达到无生成需求的高效学习。
结果:当与 Vision Transformers 结合时,I-JEPA 展现出极高的可扩展性。在不到 72 小时内使用 16 个 A100 GPU 就能在 ImageNet 上训练 ViT-Huge/14,并在线性分类、对象计数、深度预测等多种任务中表现出色。下游性能大大提高,比使用 MAE 预训练的 ViT-H/14 高效超过 10 倍。
读后感
之前的方法要么专注于学习图像的本质(表征),要么关注表象(像素级),而 I-JEPA 则作为一种自监督学习方法,同时捕捉图像的语义和细节特征。与传统的生成式方法(如 MAE)不同,I-JEPA 的主要特点有:
- 非生成式:I-JEPA 不是重建原始图像,而是在嵌入空间中预测目标区域的表示。
- 嵌入空间预测:损失函数在嵌入空间中计算,这样避免了对像素级细节的过度关注,更专注于语义特征的学习。
这种方法使模型能够学习更具语义的表片,同时减少对低级细节的依赖。
这篇论文发布较早,其目标区域与上下文块的对比虽然更完整,但不一定完全代表完整的语义。若有更好的标注数据(如机器标注),模型可能会学习到更加抽象,甚至与人类意象相对应的表征。
1 介绍
在计算机视觉领域,主流的自监督学习方法主要分为两类:
- 不变性学习:如 SimCLR 和 BYOL,这些方法通过编码同一图像的不同视图,使其表示尽量接近,从而得到语义一致的嵌入。然而,它们通常依赖大量手工设计的数据增强(例如随机裁剪和颜色扰动),这可能引入过多先验偏置,导致在不同数据分布的任务中表现不佳。
- 生成式方法:直接重建被遮挡的图像区域。这种方法擅长捕捉细节,但因训练目标在像素级别,容易使模型过度关注低层特征而忽略语义信息。
在本研究中,我们探讨如何不依赖图像变换的额外先验知识,提高自监督表示的语义水平。I-JEPA(基于图像的联合嵌入预测架构)提出了一种折中方法:它汲取了生成模型“预测缺失信息”的精髓,但与之不同的是,I-JEPA 并不重建图像本身,而是预测目标块在嵌入空间中的表示,避免像素级还原,直接引导模型学习更抽象、更高层次的语义表示。
这一思路也可以从能量模型(EBM)的角度进行理解:
- 传统能量模型为“兼容的输入 - 输出对”分配低能量(即高相似度),而为不兼容的输入分配高能量。
- I-JEPA 将该原则应用于表示空间:上下文和目标嵌入相似 ⇒ 表示一致 ⇒ 能量低。
2 背景
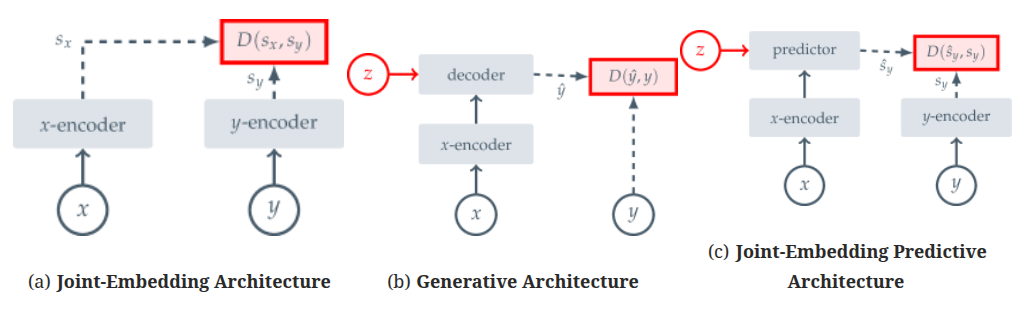
图 -2 直观地展示了三种架构的区别
在联合嵌入架构(Joint Embedding Architecture, JEA)中,模型旨在学习一个嵌入空间,使得兼容输入对(如同一图像的不同视图)在空间中的表示相似,而不兼容输入对(如不同图像)的表示差异显著。这种方法常用于对比学习,如 SimCLR 论文阅读_对比学习_SimCLR 和 MoCo。
对于生成式架构(Generative Architecture),它从兼容信号 x 直接重构信号 y,利用条件变量 z 的解码器网络实现重构。这里,x 是图像 y 的部分掩码副本,z 包含可学习的掩码和位置信息,指示需要重构的图像部分。只要 z 的信息量低于 y,这类架构就能避免表征崩溃,如 MAE 论文阅读_MAE。
联合嵌入预测架构(Joint Embedding Predictive Architecture, JEPA)与生成式架构概念相似,但核心区别在于其损失函数施加于嵌入空间,而非输入空间。JEPA 通过学习兼容信号 x 的嵌入来预测信号 y,借助一个以附加(可能是潜在)变量 z 为条件的预测器网络辅助完成预测。
这种方法的优势在于,它专注于语义层面的表示学习,而非像素级重建,从而增强模型捕捉语义信息的能力。同时,JEPA 也可能面临表示崩溃的问题;我们通过 x 和 y 编码器的非对称架构设计来防止这种崩溃。
2.1 方法
目标如下:根据给定的上下文块,预测不同目标块的表示。
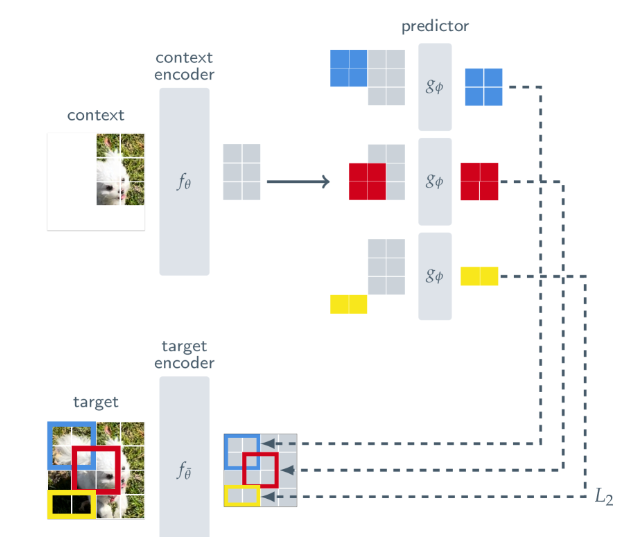
图 3 详细描述了 I-JEPA 的核心流程:
- 模型从图像中选取一个上下文块(如右上区域),通过上下文编码器(ViT)提取其表示;
- 随后,模型试图预测图像中多个目标块(被遮挡区域)的表示;
- 预测器网络将上下文表示与位置信息结合,输出目标块表示的预测;
- 真实的目标表示由另一个称为目标编码器的网络生成。目标编码器的参数通过上下文编码器参数的指数移动平均(EMA)更新,以避免表示崩溃。
我们在上下文编码器、目标编码器中均使用 ViT 架构。训练时,模型通过最小化预测表示与目标表示之间的 L2 距离来优化参数。这一机制使得模型无需直接看到目标块像素,也能凭借上下文信息“想象”这些位置的语义表示。

图 4 展示了上下文和目标掩蔽策略示例。对于一幅图像,我们随机采样 4 个目标块,比例在 0.15 至 0.2 之间,长宽比在 0.75 至 1.5 之间。接着,再随机采样一个上下文块,比例在 0.85 至 1.0 之间,确保其不与目标块重叠。此策略下,目标块具备相对的语义信息,而上下文块则信息丰富且稀疏,提高了处理效率。
预测器 gϕ(·, ·) 接受上下文编码器 sx 的输出和待预测块的掩码标记 \(\{mj\}_{j∈Bi}\) 作为输入,输出块级预测 \(ˆsy(i) = \{ˆs_{yj}\}_{j∈B_i} = g_ϕ(s_x, \{m_j\}_{j∈Bi})\)。掩码标记通过一个附加位置嵌入的共享可学习向量进行参数化。
预测器 ϕ 和上下文编码器 θ 的参数通过梯度优化进行学习,而目标编码器 ¯θ 的参数则通过对上下文编码器参数进行指数移动平均更新。研究表明,使用指数移动平均的目标编码器对 Vision Transformers 的 JEA 训练至关重要,我们发现对于 I-JEPA 也同样重要。
3 实验
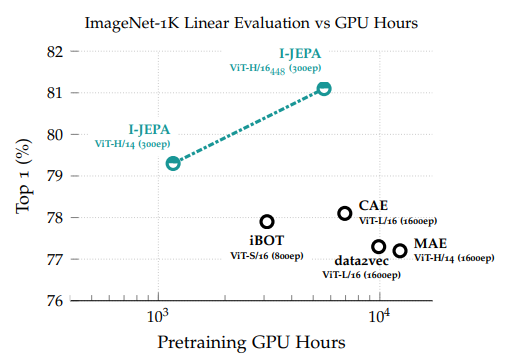
表 1 展示了图像分类任务中在常用 ImageNet-1K 线性评估基准上的性能。
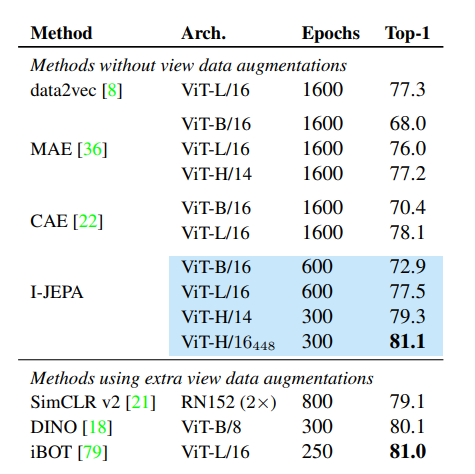
I-JEPA 在计算效率方面表现出显著提升,并学习到更具语义的现成表示。与我们的研究同步,data2vec-v2 探索了适用于多模态学习的高效架构,而 iBOT 将 data2vec 风格的块级重建损失与 DINO 的视图不变性损失结合,此方法需要处理每个输入图像的多种用户生成视图,限制了其可扩展性。
相比之下,I-JEPA 展现出高度的可扩展性。具体而言,大型 I-JEPA 模型 (ViT-H/14) 的计算需求低于小型 iBOT 模型 (ViT-S/16)。此外,我们发现使用更大规模的数据集进行预训练可以提升 I-JEPA 的效果。

4 相关论文
- EBMs: A tutorial on energy-based learning. Predicting structured data 论文阅读_基于能量的学习
- JEPA: A path towards autonomous machine intelligence version 论文阅读_LeCun_迈向自主机器智能之路