论文阅读_语义嵌入_电子商务搜索中的多阶段多粒度学习
1 | 英文名:Learning Multi-Stage Multi-Grained Semantic Embeddings for E-Commerce Search |
1 读后感
论文的使用场景是海量数据的电子商务搜索,目的是在十亿级语料库中找到相关项目,同时确保低延迟和计算成本。这项工作的痛点在于检索阶段需要整合多级信息。
当前的主流技术是基于嵌入的检索方法,采用双塔框架分别学习查询和项目的嵌入向量,从而利用高效的近似最近邻(ANN)搜索来检索相关项目。现有的搜索系统主要采用“检索 - 预排序 - 排名”的多阶段架构。这篇论文主要讨论检索阶段。
整体而言,是针对不同阶段组织不同数据训练模型,具体方法的通用性不强,但整体和局部结合,同时考虑多阶段效果等方法可以举一反三。算法偏应用,并不复杂,也确实结合了具体场景,解决了实际问题。
这里有一个值得思考的现象:用户的查询和点击行为不一定一致,这可以视为理论结果和实际结果的错位。比如,我想买健康食品,却被一个奇怪的商品吸引,点开了它。而搜索系统通常会根据查询提供结果,而较少考虑用户的点击行为。
另外,不仅可以对文本做嵌入,还可以根据不同目标,对用户其它特征和产品特征进行嵌入。在这里,嵌入更像是一种特征提取或映射,针对目标提取一些隐藏或组合特征,以供下一步使用。
2 摘要
目标: 提出通过学习多层次多粒度语义嵌入(MMSE)来改进嵌入式检索(EBR)方法,以应对工业多阶段搜索系统中用户行为不一致的问题。
方法: 利用多阶段信息挖掘来处理实际用户行为数据中的已订购、已点击、未点击和随机抽样的项目,并通过后融合策略捕捉查询与项目的相似性,同时提出多粒度学习目标,将检索损失与全局比较能力以及排序损失与局部比较能力结合起来生成语义嵌入。
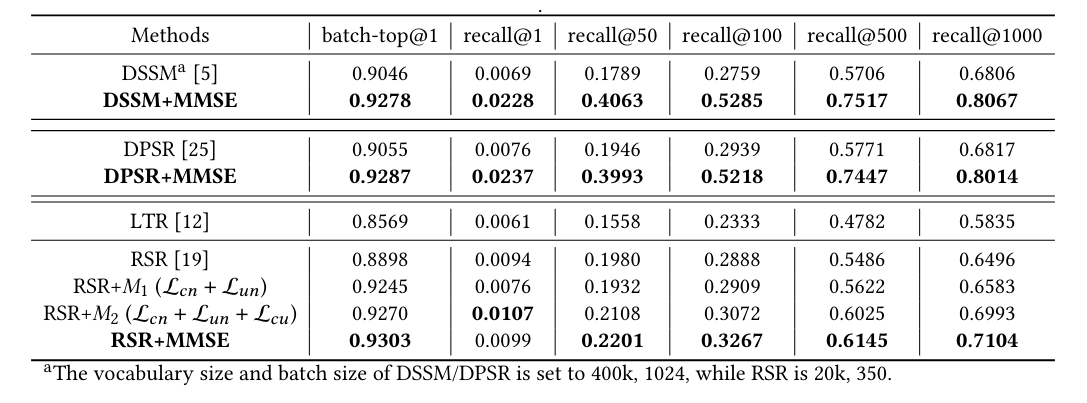
结果: 在真实的十亿级数据集和在线 A/B 测试中,MMSE 在离线召回率和在线转换率(CVR)等指标上显著提高了性能。
3 方法
目标是将用户查询、用户特征、产品特征和产品描述都编码成嵌入信息。然后将这些嵌入信息代入模型进行训练。训练时,同时考虑检索损失(全局)和排序损失(局部),以多个目标共同优化模型。最终,训练得到的 User Encoder 模型和 Item Encoder 模型分别用于对用户和商品进行编码,以供进一步的预测。在此过程中,同时考虑了用户的排序和点击行为。
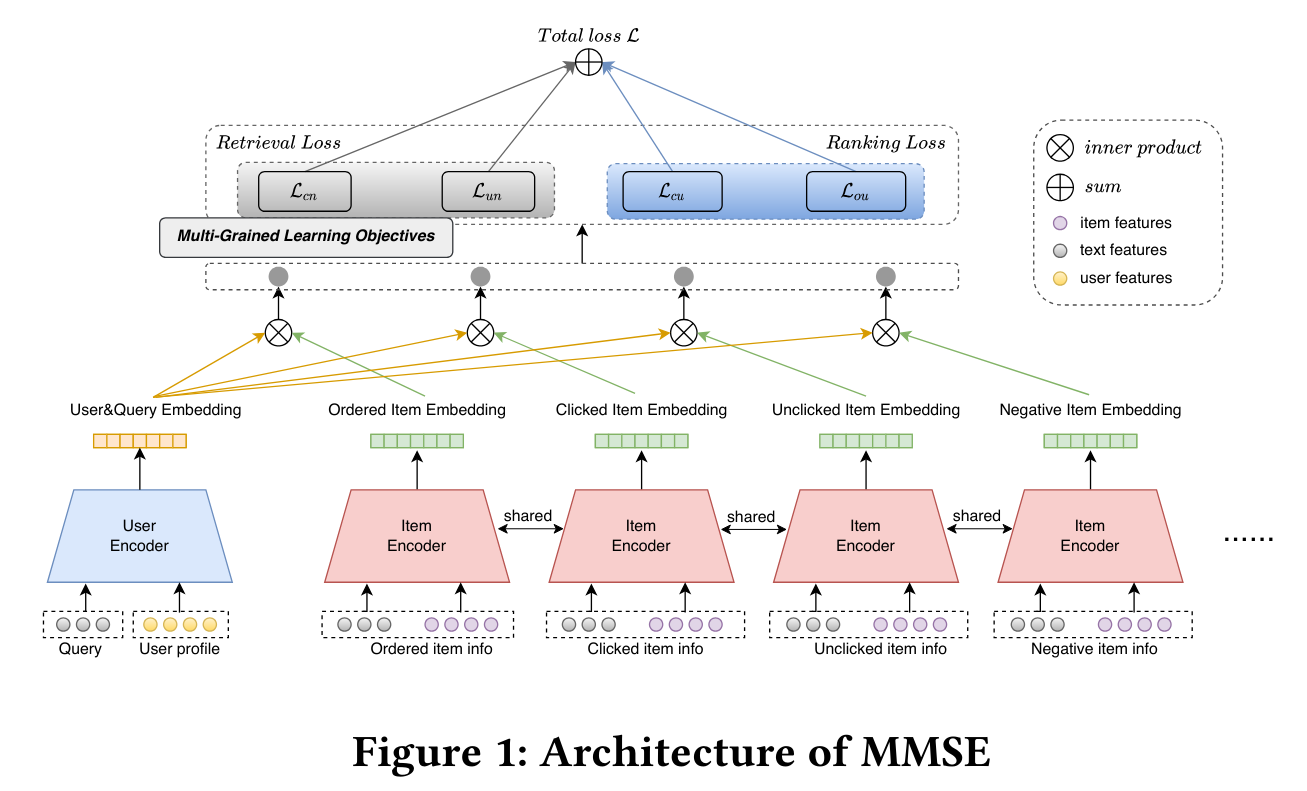
3.1 双塔结构
典型的电商检索解决方案采用双塔模型架构。双塔模型的核心设计是将查询和项目嵌入分开学习,从而方便项目嵌入的离线计算,提高检索效率。
该架构由查询塔 𝑓𝑞(⋅) 和项目塔 𝑓𝑝(⋅) 组成,分别处理查询和项目特征。在电子商务数据上预先训练 4 层 Transformer 模型。然后,我们可以部署一个评分函数 𝑆(𝑞, 𝑝) 来计算查询和项目之间的相似度,具体实现为点积操作。
3.2 多阶段信息挖掘
文章提出了多阶段信息挖掘,给定一个用户及其查询 𝑞,用户订购项 𝑃𝑜 的嵌入集、用户点击项 𝑃𝑐 的嵌入集和用户未点击项 𝑃𝑢 的集合。另外,采用混合方法选择两个负样本源并生成负样本集 𝑃𝑛。对于每个用户查询 𝑞,对应的多阶段信息可以表述为
𝑃=[𝑃𝑜, 𝑃𝑐, 𝑃𝑢, 𝑃𝑛]。其中,Po 是 Pc 的子集。
3.3 多粒度学习目标
这里考虑了多个损失函数,最终的损失函数是以下损失之和:
- 点击与负对指标:从所有候选者中查找与查询相关的 top@𝐾 项。
- 未点击与负对指标:期望未点击项与查询的相似度大于负例。
- 点击与未点击指标:期望点击项比未点击项排序更靠前,并计算排名损失。
- 定购与未点击指标:期望定购项与未点击项差异更大,并计算排名损失。
4 实验