基于解码器的时间序列预测基础模型
1 |
|
摘要
- 目标:基于大型语言模型在自然语言处理中的进展,设计一个用于预测的时间序列基础模型。
- 方法:基于对大型时间序列语料库进行预训练的修补解码器风格注意力模型。
- 结论:该模型在多个公共数据集上的开箱即用零射击性能接近各个数据集的最先进监督预测模型的准确性。能够很好地适用于不同的预测历史长度、预测长度和时间粒度。
读后感
这是一个单变量预测工具,我觉得只是验证了一种可能性,实用性不是很强。其基础模型参数大小为 200M,预训练数据大小为 100B。该工具的零样本性能可以与全监督方法在处理不同时间序列数据的准确性上类似。
模型采用了仅解码器的 Transformer 结构。其核心方法是 Patch Masking,这种方法结合了 GPT 和 BERT 的特性。它像 BERT 一样,通过使用 MASK 遮蔽来实现自我监督学习。同时,它又像 GPT,作为一个解码器模型,它是单向的,只能利用过去的数据来预测未来。MASK 则用于控制生成不同长度的学习。
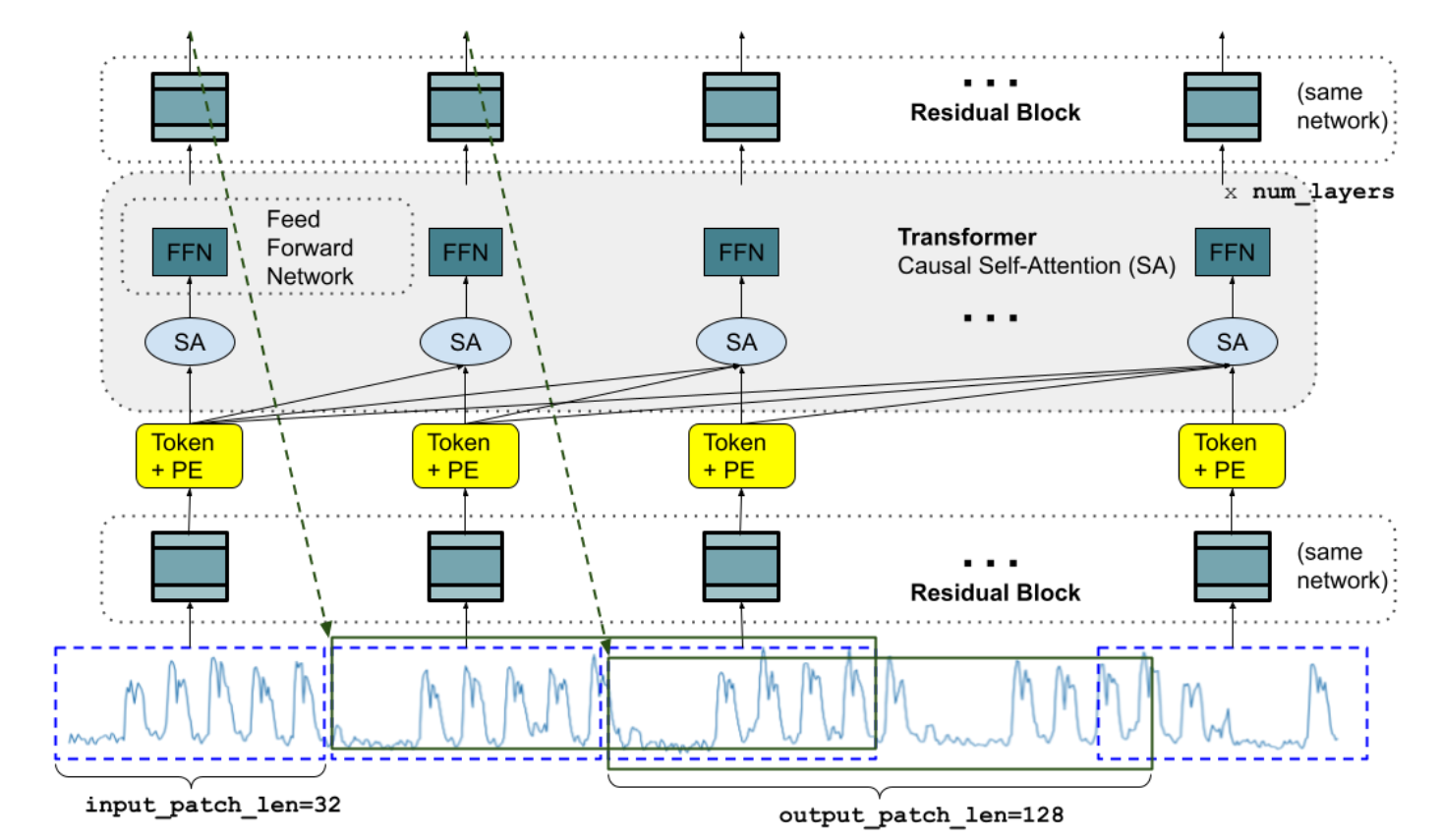
一个特定长度的输入时间序列可以被分解成多个输入片段,每个片段都会经过一个残差块的处理并转化为一个向量。这个向量的维度与变压器层的模型维度相匹配。随后,这个向量会添加位置编码,然后被送入若干个堆叠的 Transformer 层中。在这里,"SA" 代表自注意机制,它使用了多头因果注意意;FFN 则代表全连接层。最后,输出的令牌会通过残差块映射到一个大小为 output_patch_len 的输出。
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.