论文阅读_MoE_Switch Transformers
1 | 英文名称: Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity |
读后感
MoE 相对于原始的 Transformer 来说是一个稀疏模型,其中包含多个专家模型。在不同场景下通过路由调用不同的模型进行计算。具体方法如图 -2 所示,该方法将 Transformer 中的 FFN 变成了选择某个具体的 FFN 进行路由操作,而其它模块(非蓝色部分)则保持不变,由各个专家共用。
从论文的角度来看,其提出了训练一个巨大模型,并在不同区域存储不同知识的概念。通过广泛地调整参数达到某种平衡,在推理时只使用其中一两个子模型以提高推理速度,从而得到一个稀疏且高效的解决方案。如果将这个逻辑推广开来,则可以将路由部分设计成一个小模型;不同功能可以通过不同的模型实现;然后将结果组合起来得到最终输出,从而利用模型集群解决不同问题。目前看来,这也是一种常见的策略。
我觉得这有点像大脑,大脑的不同区域负责处理不同任务,MoE 将不同知识存储在不同区域,似乎也是基于这个假设,但完全依靠模型自身进行学习。这点似乎可以进一步优化。
摘要
目标:解决混合专家模型(Mixture of Experts, MoE)在复杂性、通信成本和训练稳定性方面的问题,同时提高训练速度和多语言处理性能。
方法:通过引入 Switch Transformer,简化 MoE 路由算法,并采用新的训练技术和低精度格式(bfloat16)来训练大型稀疏模型。
结果:新模型在多语言环境中的性能超过了 mT5-Base 版本,并在 "Colossal Clean Crawled Corpus" 上预训练了高达万亿参数的模型,实现了比 T5-XXL 模型快 4 倍的速度。
引言
文章贡献
- Switch Transformer 架构,比 Mix of Experts 更简单和先进。
- 即使在计算资源有限的情况下,只需使用两名专家,也能实现改进。
- 成功地将稀疏的预训练和专门的微调模型提炼成小型密集模型。将模型大小减少了多达 99%,同时保留了大型稀疏教师的 30% 的质量增益。
- 改进了预训练和微调技术:(1)选择性精确训练,支持以较低的 bfloat16 精度进行训练,(2)允许扩展到更多专家的初始化方案,(3)增加专家正则化,改进稀疏模型微调和多任务训练。
- 对多语言数据,发现所有 101 种语言都有普遍的改进,91% 的语言受益于 mT5 基线的 4 倍 + 加速。
- 通过有效地结合数据、模型和专家并行性来创建具有多达一万亿个参数的模型,从而扩大了神经语言模型的规模。这些模型将强调的 T5-XXL 基线的预训练速度提高了 4 倍。
方法
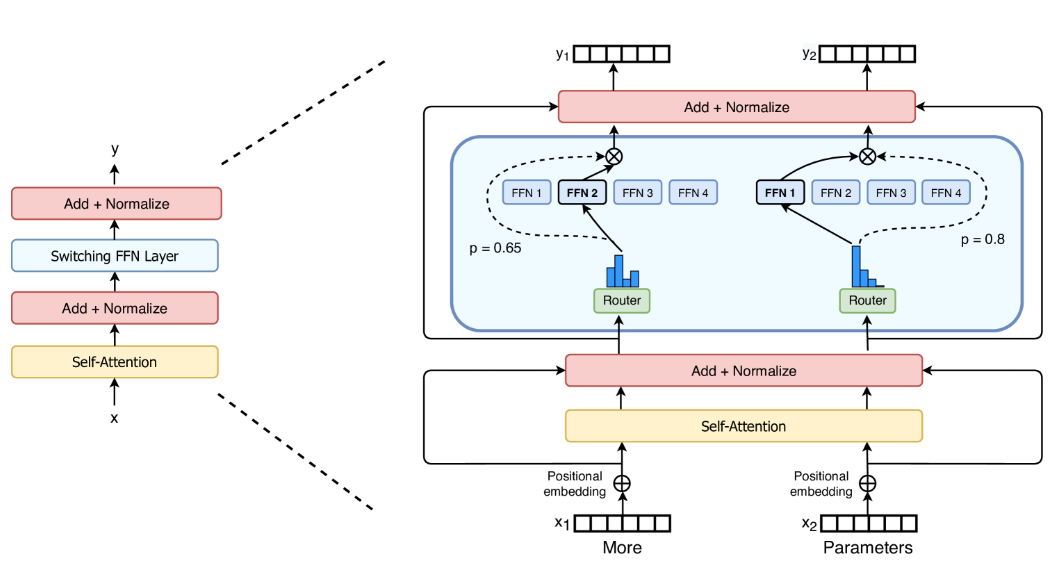
图 2:开关 Transformer 编码器模块的示意图。用稀疏的开关 FFN 层(浅蓝色)替换了 Transformer 中存在的密集前馈网络(FFN)层。该层对序列中的 token 独立运行。绘制了两个令牌( x1=“More” , x2=“Parameters” )在 FFN1,FFN2,FFN3,FFN4 专家之间路由(实线),路由器独立路由每个 token。交换机 FFN 层返回所选 FFN 的输出乘以路由器门值(虚线)。