论文阅读_嵌入_中文嵌入资源
1 | 中文名:C-Pack:推进一般中文嵌入的打包资源 |
读后感
这篇论文的核心是:通用的中文文本嵌入。
读完之后,会对中文嵌入的模型效果、模型架构、评测方法和训练数据有更直观的了解。文档风格简洁明了,行动导向。
文中介绍的 BGE 模型是 Obsidian 插件 Smart Connection 的默认嵌入模型。我使用过,效果不错,速度也很。
摘要
目标: 介绍了 C-Pack,这是一个显著推进通用中文嵌入领域的资源包。
方法: C-Pack 包括三个关键资源:C-MTEB(涵盖 6 项任务和 35 个数据集的综合基准)、C-MTP(从标记和未标记中文语料中整理的大规模文本嵌入数据集)以及 BGE(BAAI 通用嵌入:覆盖多种规模的嵌入模型家族)。
结果: 模型 BGE/C-TEM 参数少,成本低,效果好,在 C-MTEB 上比之前的所有中文文本嵌入表现高出最多 10%,并且我们的英文文本嵌入模型在 MTEB 基准上达到了最新的性能标准。
1 引言
应用场景的多样性要求一个统一的嵌入模型。这个通用模型需要能够处理任何应用场景(例如,问答、语言建模、对话)中的各种用法(如检索、排序、分类)。
开发通用文本嵌入需要综合考虑多个因素,包括数据、编码器模型、训练方法和基准测试。这些因素共同驱动模型的改进。
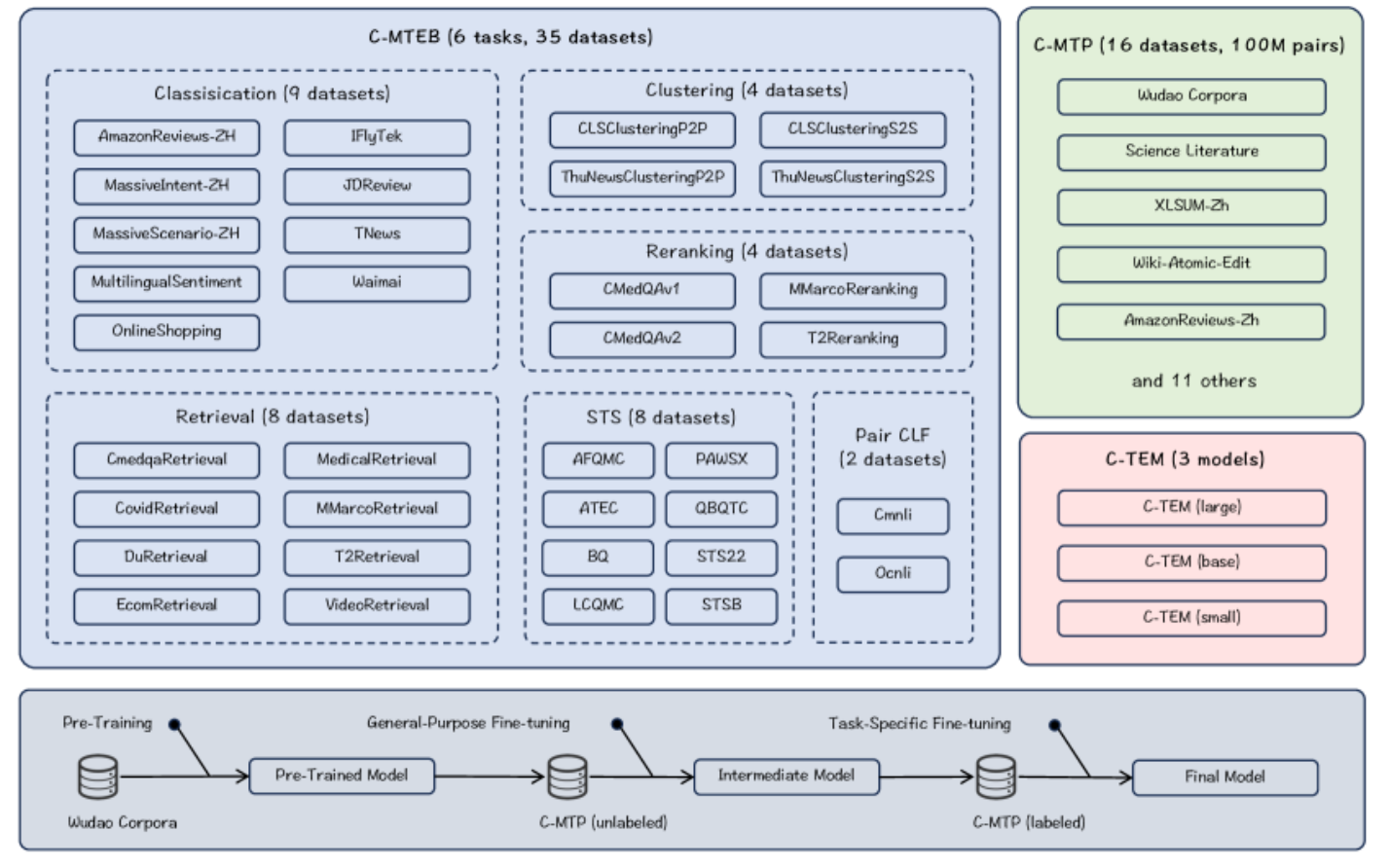
2 C-Pack
2.1 Benchmark: C-MTEB
为了全面评估中文嵌入的通用性,创建了 C-MTEB。我们进行了以下重要工作:
- 全面收集数据集
- 将数据集分类为文本嵌入的不同能力属性,例如检索、相似性分析、分类等
- 标准化评估协议
- 建立评估管道
总共收集了 35 个与中文文本嵌入评估相关的公共数据集。评估任务分为以下 6 组:
- 检索(快速):对于每个查询,在语料库中找到 Top-k 相似的文档。
- 重排序(精细):根据嵌入相似性对每个查询检索出的文档进行重新排名。
- STS(语义文本相似性):根据两个句子的嵌入相似性衡量它们的相关性。遵循 Sentence-BERT 方法,用 Spearman 相关系数计算结果,并作为主要指标。
- 分类:在分类任务中重用 MTEB 中的逻辑回归分类器,并以平均精度作为主要指标。
- 配对分类:处理一对输入句子,其关系由二值标签表示,通过嵌入相似性预测这种关系。
- 聚类:将句子分组为有意义的聚类。按照 MTEB 的设置,使用小批量 k-means 方法进行评估。批次大小为 32,k 值等于小批量中的标签数。
C-MTEB 的 Python 工具已在 GitHub 上提供,可直接使用。
2.2 训练数据:C-MTP
用于一般中文嵌入的训练。成对的文本构成了文本嵌入训练的数据基础,例如,一个问题及其答案、关于同一主题的两个文档。大多数数据来源于对大量未标记数据的整理,约有 1 亿个配对文本;另一小部分来自高质量标记数据的全面集成,即 C-MTP(标记),总计约有 100 万个配对文本。
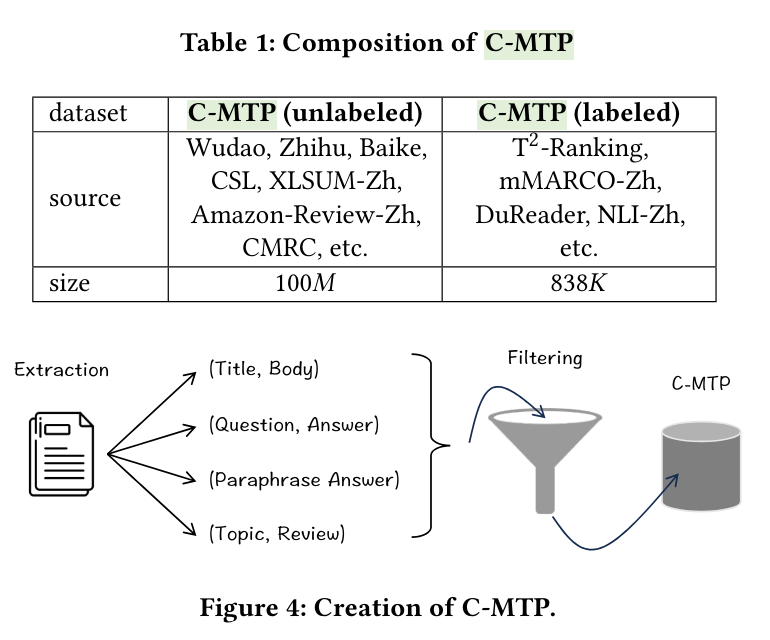
未标记数据:从纯文本中提取丰富的语义成对结构,例如释义、标题和正文。为保证数据质量,采用复合数据清理策略优化原始数据。首先,进行一般过滤,去除非文本内容、重复内容和恶意内容。其次,通过语义过滤进一步处理数据,确保文本对在语义上相关。使用第三方模型 Text2VecChinese 对每个文本对的关系强度进行评分,并删除评分过低的数据。
标记数据来自 TRanking、DuReader、mMARCO、CMedQA-v2、multi-cpr、NLI-Zh、cmnli 和 ocnli 数据集。
考虑到规模和质量的差异,可以将 C-MTP(未标记)和 C-MTP(标记)应用于不同的训练阶段。
2.3 模型 BGE
模型基于类似 BERT 的架构,有三种可用的刻度:大(326M 参数)、基础(102M 参数)和小型(24M 参数)。验证表明,与 BGE 中的原始模型及其他通用预训练编码器(如 BERT)的微调模型相比,微调模型在应用中表现更好。
2.4 训练过程
训练过程由三个主要组成部分:
- 预训练:使用纯文本进行训练,利用 Wudao 语料库。这是一个用于汉语模型预训练的庞大而高质量的数据集。被污染的文本被编码到嵌入空间中,通过轻量级解码器恢复干净文本,并使用 RetroMAE 作为损失函数。
- 通用精调:使用未标记的 C-MTP 进行对比学习。通过区分配对文本和负例,利用 batch 内样本作为负例。
- 特定任务精调:使用标记的 C-MTP 进行多任务学习。由于任务类型不同,其影响可能会相互矛盾。通过明确区分任务指令和改进负采样方法,减轻任务间相互矛盾的影响。
3 实验
3.1 通用模型评测
主实验是中文 Embedding 评测,结果如表 -2 所示:
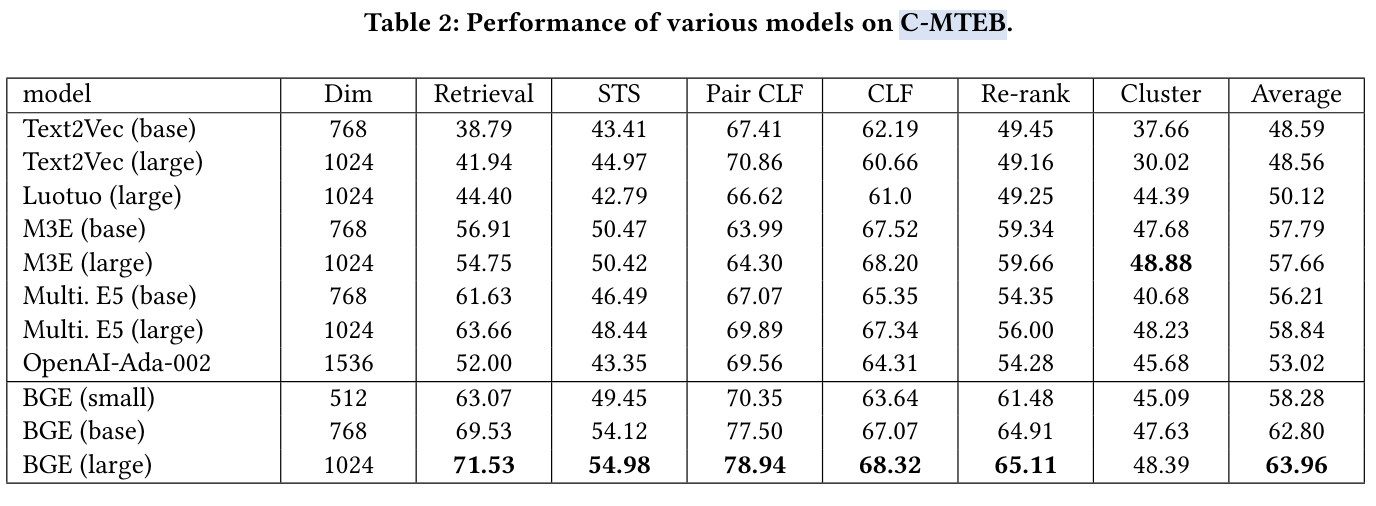
BGE 在中文文本嵌入性能上显著优于现有方法。它在检索任务中表现尤为出色,其次是在 STS、配对分类和重新排名任务中。尽管模型大小和嵌入维度的增加会提升性能,但即使是最小的 BGE 模型,效果也相当不错。
表 3 和表 4 分别展示了消融实验以证明训练步骤的有效性以及不同批量大小(batch size)的影响。表 5 则是英文排行榜,这里不再展示图片。
4 当前排行榜
https://huggingface.co/spaces/mteb/leaderboard