论文阅读_大图的节点表征GraphSAGE
介绍
英文题目:Inductive Representation Learning on Large Graphs
中文题目:基于大图的归纳表示学习
论文地址:https://arxiv.org/abs/1706.02216
领域:知识图谱,知识表征
发表时间:2017
作者:William L. Hamilton,斯坦福大学
出处:NIPS
被引量:2398
代码和数据:https://github.com/williamleif/GraphSAGE,pyg 和 dgl 均有对该方法的支持
阅读时间:2022.05.03
读后感
学习大图、不断扩展的图,未见过节点的表征,是一个很常见的应用场景。GraphSAGE 通过训练聚合函数,实现优化未知节点的表示方法。之后提出的 GAN(图注意力网络)也针对此问题优化。
文中提出了:传导性问题和归纳性问题,传导性问题是已知全图情况,计算节点表征向量;归纳性问题是在不完全了解全图的情况下,训练节点的表征函数(不是直接计算向量表示)。
图工具的处理过程每轮迭代(一次 propagation)一般都包含:收集信息、聚合、更新,从本文也可以更好地理解,其中聚合的重要性,及优化方法。
泛读
- 针对问题:大图的节点表征
- 结果:训练出的模型可应用于表征没见过的节点
- 核心方法:改进图卷积方法;从邻居节点中采样;考虑了节点特征,加入更复杂的特征聚合方法
- 难点:需要预先了解图卷积网络
- 泛读后理解程度:直接精读
(看完题目、摘要、结论、图表及小标题)
精读
摘要
使用低维向量表示大图中的节点对下游的预测任务非常有用,但目前方法大多依赖训练集中所有节点;这些方法具有传导性,但不能用于没见过的节点。文中提出了GraphSAGE方法,这是一个通用的归纳框架,它均衡节点的特征信息,并可为未见过的节点构建有效的词嵌入方法。与之前为每个节点训练单独的嵌入向量不同,文中方法学习一个函数利用从节点近邻中采样和聚合特征来构建新的节点嵌入。
1. 介绍
使用低维向量表示大图中节点的基本思路是把稀疏数据压缩到稠密的低维度,然后应用于下游的分类、聚类、链接预测等任务中。
之前方法大多应用于单一固定图,而实际应用中需要快速嵌入之前没见过的节点,或者将模型应用于全新的图,即需要归纳能力:操作不断演进的图和未见过的节点。
相对于传导,归纳方法更为复杂,因为它需要将未见过的节点或图与之前的学习“对齐”。因此,归纳框架必须能学到节点邻居的结构,用于描述局部和全局的情况。
如果想将之前的传导方法应用于未见的节点,在预测之前,还需要额外的训练。之前提出的 GCNs 将卷积方法应用于传导的图嵌入,效果很好。本文将 GCNs 扩展到无监督的归纳学习中,又加入了可学习的聚合方法。
GraphSAGE(SAmple and aggreGatE)用于归纳地学习图中节点的嵌入。与之前基于矩阵分解的方法不同,它的目标是嵌入未见过的节点(事先没矩阵没法分解),因此,它需要更好利用节点特征,同时学习拓补结构和邻居特征的分布,因此,着重处理特征较多的图;同时利用图的结构,也能处理无节点特征的图。
与之前直接生成节点编码不同,文中方法训练聚合函数来优化聚合邻居特征的方法。在预测和测试时,使用训练好的模型计算词嵌入。通过定义损失函数,在无监督任务中也能学习(将结构作为学习目标),也可以学习有监督任务。
2. 相关工作
基于因式分解的嵌入方法
最近常见学习图嵌入的方法是基于随机游走的统计方法和基于矩阵分解的方法。这些方法直接学习各节点的嵌入,如想应用于新节点,则需要额外训练。与之前方法不同:文中方法使用节点特征训练模型,来预测未知节点。
图上的有监督学习
之前常用基于核的方法,有监督地学习图中结构,根据各种各样的核提取节点向量。后来出现基于神经网络的有监督学习,它们通过学习图结构实现具体功能,比如用于整图的分类。而文中提出的方法主要用于表征图中的节点,可使用无监督数据训练。
图卷积网络
近年来卷积神经网络被用应于图学习,已提出的一些方法都不太适用于大图,Kipf 提出 GCNs 算法是一个用于传导的半监督算法,它在训练时需要全图的拉普拉斯矩阵,文中方法可视为 GCNs 的变体,具体在 3.3 中讨论。
3. 建议的方法:GraphSAGE
简单地说:为了得到中间红色节点的表征,先从邻域中采样(左图),利用邻居蓝色节点聚合出红色节点;而蓝色节点又是根据其邻居绿色节点聚合出来的;通过迭代计算邻居信息,最终生成红色点的表征,它聚合了与它距离较近(直接)和较远(间接)的节点信息(中图),最终在下游任务中使用学到的节点表征。
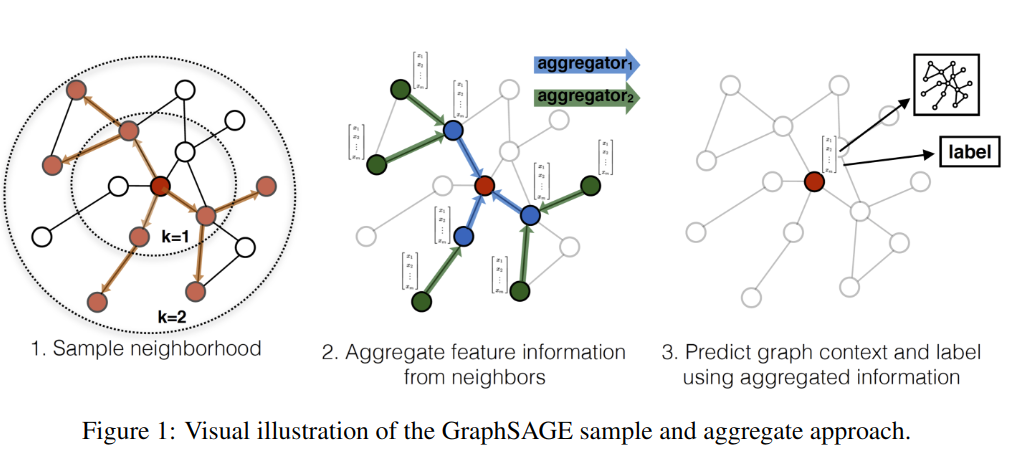
3.1 生成嵌入算法
假设模型参数已经训练好,学习了 K 个聚合函数,AGGREGATEk, ∀k ∈ {1,..., K}),它从邻居节点聚合信息,训练 K 个权重矩阵 Wk(训练方法见 3.2)。
算法 -1 展示了如何利用模型生成新的节点嵌入:

其中 v 是目标节点,u 是 v 的邻居节点,输入特征用 x 表示,hk 是节点在第 k 层的表征;第 4 行,节点 v 聚合它邻居在上一层表征作为 HK(v)k,第 0 次表征为输入 x;第 5 行,串联 v 点在上层的表征和 HK(v)k,通过矩阵 W 和激活函数转换后生成该点在本层的表征;第 7 行对表征做规范化;第 9 行将最后一层表征作为输出。其中聚合函数可以有多种。
算法背后的逻辑是:每一次迭代,节点都从它的近邻聚合数据,经过多次迭代,节点逐渐从离它更远的部分获得越来越多的信息。
对于 minibatch 的操作方法,详见附件 A。
与 Weisfeiler-Lehman 同构实验的关系
GraphSAGE 算法的概念灵感来自于测试图同构的经典算法(GCN 也可看作是 WL 的变形)。WL 算法详见:什么是Weisfeiler-Lehman(WL)算法和WL Test?
GraphSAGE 是 WL 测试的近似,用 GraphSAGE 生成节点表示而不是用 WL-test 测试同构,所以,使用训练的神经网络聚合器替换 hash 函数。GraphSAGE 和经典的 WL 测试之间的联系为文中的算法设计学习节点邻域的拓扑结构提供了理论背景。
定义邻域
文中方法统一抽样一组固定大小的邻居,而非使用算法 1 中所有的邻居,这是为了保持每个 batch 的一致性,将 N(v) 定义为取固定大小的邻居。在不同的迭代中使不同的均匀样本。
如果不采样,那么内存和运行时间将不可预测,在最坏的情况下可能达到
O(|V|);固定后的复杂度是: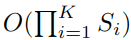
其中 S 和 K 是用户定义的常量,当 K=2,S1.S2<=500 时可实现高性能。
3.2 学习 GraphSAGE 参数
设计的损失函数,鼓励相近的节点具有相似表征,不同的节点有较大差异。使用随机梯度下降调参权重矩阵 Wk。
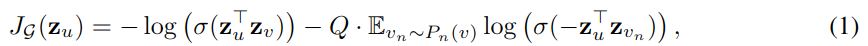
其中 zu 是输出的表征,v 是 u 在指定随机步以内 u 的共现节点,σ 是 sigmoid 激活函数,Pn 是负例分布,Q 是负例个数。与之前方法不同的是,zu 是从局部领域中包含的特征生成的,而不是为每个节点训练的嵌入。
上面描述了无监督任务中利用节点特征计算损失函数优化模型的方法,其结果可以作为服务或者存储供下游任务使用,对于特定的有监督学习下游任务,也可以替换或添加损失函数来训练模型。
3.3 聚合器架构
节点的邻居没有顺序,因此,算法 -1 中的聚合方法需要操作无序向量,聚集器需要是对称的(不随其输入的排列而变化),同时是可训练的并保持较高的表示能力。文中研究了三种聚合器:
Mean aggregator
均值聚合,即简单地对近邻取均值,它类似于传导 GCN 框架中使用的卷积传播规则,将算法 -1 中 4,5 行替换成以下方法:
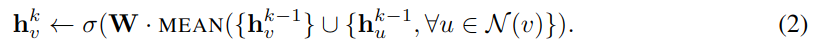
该方法类似于 GCN 方法,它是局部谱卷积粗略的线性近似,它与我们提出的其它几种方法的差别是不使用 concat 串联操作。而串联可视为在不同层间的“跳级”,能够提升性能。
LSTM aggregator
LSTM 方法相对复杂,与均值聚合相比,它有更强的表达能力,需要注意的是 LSTM 是非对称的,通过简单地将 LSTM 应用于节点邻居的随机排列,使 LSTM 适应用无序集合。
Pooling aggregator
池化聚合,使用最大池化方法从领域聚合特征,加入一个全连接层变换,然后进行最大池化。
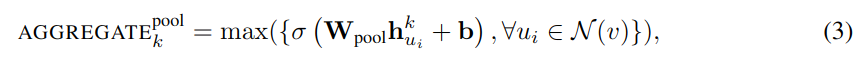
max 方法以元素为单位取最大值,σ是非线性激活函数,多层感知机(这里只用了一层)被视为利用邻居集中的节点计算特征的函数,通过最大池化又捕捉了不同方面的特征。原则上可以用平均池化代替最大池化,测试中发现没有显著差异,故实验使用了最大池化。
4. 实验
实验设置
实验对比了四个基线:随机分类,基于特征的逻辑回归(忽略图结构),DeepWalk 算法,DeepWork+ 特征;同时还对比了四种 GraphSAGE,其中三种在 3.3 节中已经说明,GraphSAGE-GCN 是 GCNs 的归纳版本。具体超参数为:K=2,s1=25,s2=10。程序使用 TensorFlow 编写,Adam 优化器。
4.1 演进图中的归纳学习
Citation 数据集
使用科学网引文数据集,将学术论文分类为不同的主题。数据集共包含 302424 个节点,平均度 9.15,使用 2000-2004 年数据作为训练集,2005 年数据作为测试集。使用节点的度以及论文摘要的句嵌入作为特征。
Reddit 数据集
将 Reddit 帖子归类为属于不同社区。数据集包含 232965 个帖子,平均度为 492。使用现成的 300 维 GloVe Common Crawl 单词向量;对于每个帖子,使用特征包含:(1) 帖子标题的平均嵌入 (2) 帖子所有评论的平均嵌入 (3) 帖子的分数 (4) 帖子的评论数量。
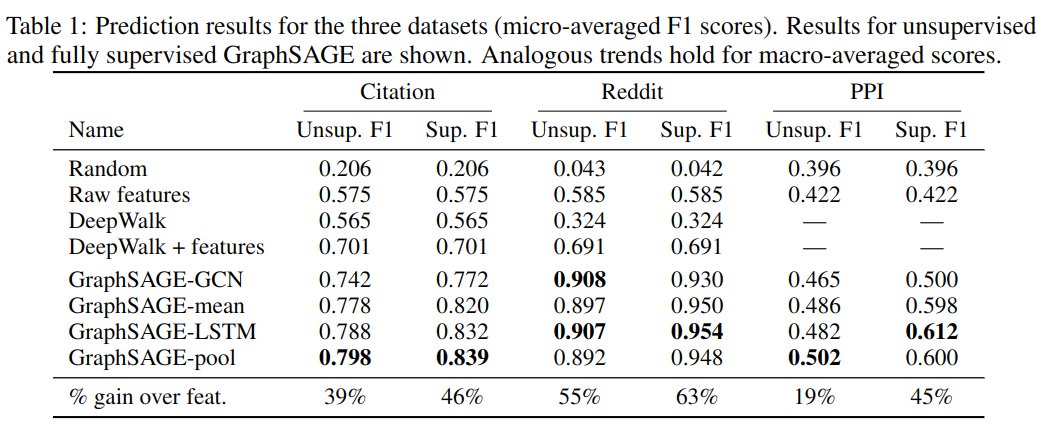
从表 -1 实验结果可以看到,GraphSAGE 方式相对于基线方法有明显提升,经过训练的聚合函数优于 GCN 方法。另外,无监督学习和有监督学习效果差不多。
4.2 跨图泛化
对于跨图泛化的任务,需要学习节点角色而不是训练图的结构。使用跨各种生物蛋白质 - 蛋白质相互作用 (PPI) 图,对蛋白质功能进行分类。在 20 个图表上训练算法,2 个图用于测试,2 个图用于验证,平均每图包含 2373 个节点,平均度为 28.8。
从实验结果可以看出 LSTM 和池化方法比 Mean 和 GCN 效果更好。
4.3 运行时间和参数敏感度
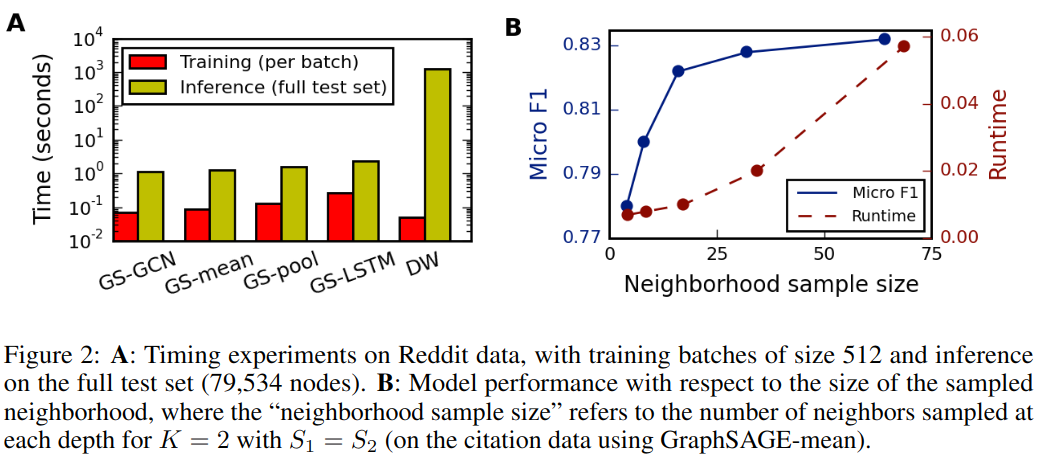
4.4 对比不同聚合函数
如表 -1 所示,LSTM 和 POOL 方法效果最好,与其它方法相比有显著差异,LSTM 和 POOL 之间无显著差异,但 LSTM 比 POOL 慢得多 (≈2x),使 POOL 聚合器在总体上略有优势。