论文阅读_医疗NLP模型_EMBERT
1 | 英文题目:EMBERT: A Pre-trained Language Model for Chinese Medical Text Mining |
读后感
针对医疗领域,利用知识图中的同义词(只使用了词典,未使用图计算方法),训练类似 BERT 的自然语言表示模型。优势在于代入了知识,具体设计了三种自监督学习方法来捕捉细粒度实体间的关系。实验效果略好于现有模型。没找到对应代码,具体的操作方法写的也不是特别细,主要领会精神。
比较值得借鉴的是,其中用到的中文医疗知识图,其中同义词的使用方法,AutoPhrase自动识别短语,高频词边界的切分方法等。
介绍
文中方法致力于:更好地利用大量未标注数据和预训练模型;使用实体级的知识增强;捕捉细粒度的语义关系。与 MC-BERT 相比,文中的模型更注重探索实体间的关系。
作者主要针对三个问题:
- 同义不同词,比如:结核病 与 痨病 指的是同一疾病,但文本描述不同。
- 实体嵌套,比如:新型冠状病毒肺炎,既包含肺炎实体,又包含新型冠状病毒实体,自身也是一个实体,之前方法只关注了整个实体。
- 长实体误读,比如:糖尿病酮酸,解析时需要关注主实体与其它实体的关系。
文章贡献如下:
- 提出了中文医疗预训练模型 EMBERT(Entity-rich Medical BERT),可学习医学术语的特征。
- 提出三种自监督任务捕捉实体层面的语义相关性。
- 使用六个中文医疗数据集评测,实验证明效果好于之前方法。
方法
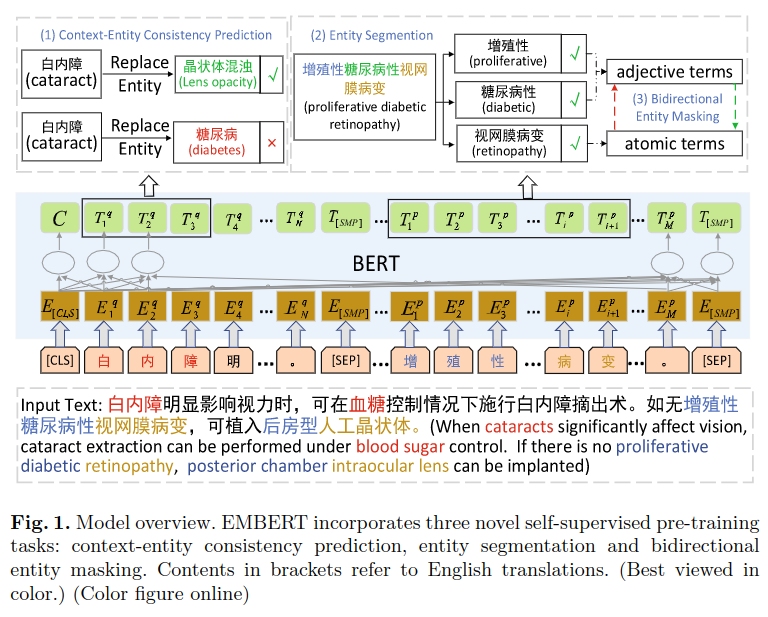
实体上下文一致性预测
利用从 http://www.openkg.cn/的知识图中取到的 SameAs 关系建立词典,用同义词替换数据集中的词构造更多训练数据,再预测被替换的实体与上下文的一致性,以提升模型效果。原理上,被替换的实体和原有实体的上下文也应具有一致性。
假设一个句子包含字 x1...xn,替换了其中的第 i 个实体 xsi,...xei,其中 s 和 e 表示替换的起止位置,其上下文指的是位置在 si 之前和 si 之后的内容,用 ci 表示。
首先,将替换后的实体编码为向量 yi:
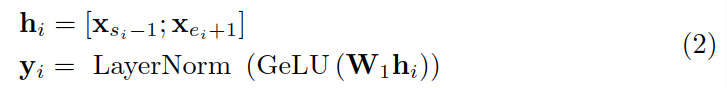
然后,利用 yi 来预测上下文 ci,并计算损失函数:
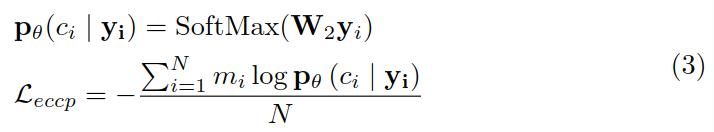
实体切分
使用基于规则的系统将长实体切分成几部分语义,并打标签,再用标注数据训练模型。
具体方法是建立一个实体词表,从训练集中获得一批高质量的医疗领域实体,与知识图中实体结合。先用AutoPhrase生成原始切分结果,计算每个片段开始和结束位置的频率,对 top-100 高频词手动检查,作为切分集。
设长实体为 xsi,...,xei,将其进一步切分 xeij,...,xeij,并将切分后小段的最后一个位置 xsij 作为切分点打标签为 1,其它位置标签为 0,训练模型来预测这个标签,将其定义为一个二分类问题。公式中的 y 是该位置 token 的向量表示。
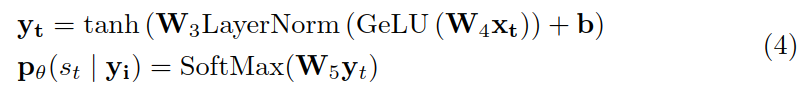
损失函数计算如下:
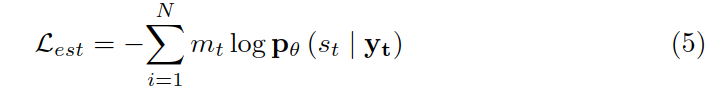
双向实体遮蔽
利用上一步方法,可把长实体分成形容词和元实体(主要的实体),遮蔽形容词,使用主实体预测它;相对的,也遮蔽主实体,用形容词预测它。
以遮蔽元实体为例,利用形容词和相对位置 p 来计算元实体的表示:
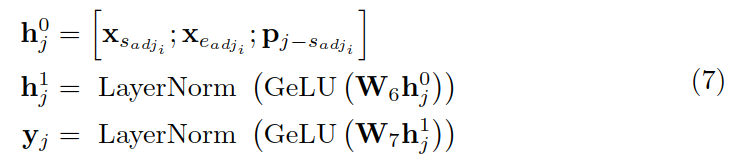
然后利用 yj 来预测 xj,并计算交叉熵作为损失函数:
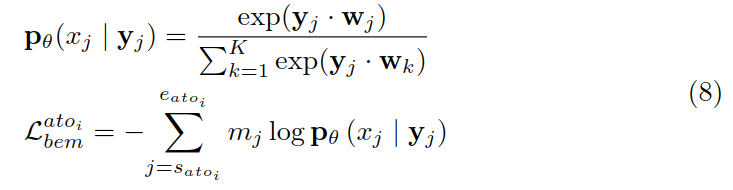
用元实体预测预测形容词也是同理,最后得到的损失函数 Lben 是两种损失的加和。
损失函数
最终的损失函数,包含 BERT 的损失 Lex 和上述三种方法的损失,λ是超参数。
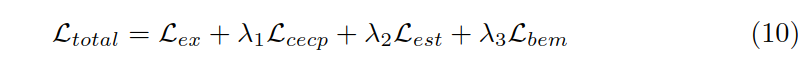
实验
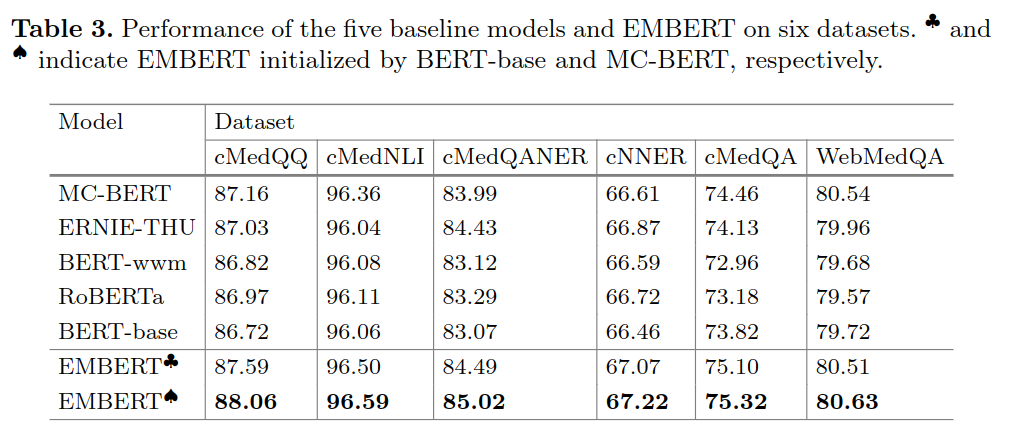
使用丁香园医疗社区问答及 BBS 数据训练模型,数据量 5G,文中使用的训练数据明显少于 MC-BERT,但效果与之相似。
主实验效果如下: