ts_tsfresh
时间序列分析工具包–tsfresh

1 简介
- 官方文档:https://tsfresh.readthedocs.io/en/latest/index.html
- 源码:https://github.com/blue-yonder/tsfresh
- Star:目前 6.1K
- 笔者推荐:看一遍官方文档,再试一下源码中的例程 tsfresh/notebooks/examples/
- 介绍:
- 可对应的长短不一的周期序列进行时间序列特征的提取。
- 能够自动地从时间序列数据中提取上百种基本的时序特征,如:峰数量,均值,最值等等
2 适用性
2.1 适用
- 自动地提取时序数据特征,扩充建模时的特征维度
- 只基于时间序列的聚类、分类和回归任务。
2.2 不适用
- 不适用于在线数据
- 不适用于对时间序列数据直接训练建模(sklearn 更加适合)。
- 不适用于高度不规则的时间序列,对于此类数据,tsfresh 可用于与时间间隔无关的特征提取(如峰值数量);但对于非等间隔的数据(如趋势)应谨慎使用。
3 安装
1 | $ pip install tsfresh |
目前版本为 0.18.0(21 年 12 月)
4 基本用法
4.1.1 下载数据
1 | from tsfresh.examples.robot_execution_failures |
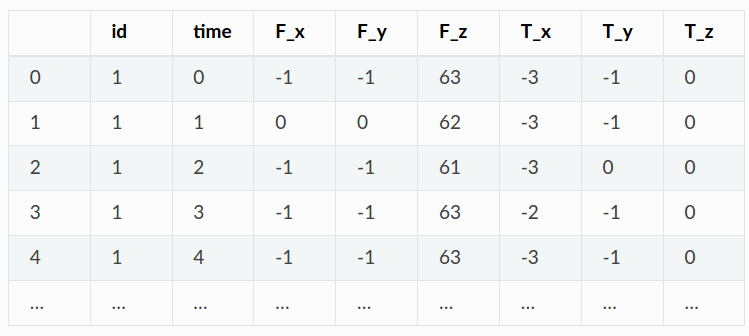
其中 id 用于区别不同机器,time 采集数据的时间点,每个机器对应 15 个时间点(0-14);F_x, F_y, F_z, x, T_y, T_z 分别采集六个传感器的值,标签 y 标记是否故障。
(上述是为格式数据,tsfresh 还支持长格式数据,以及多类传感器拆分后的数据)
4.1.2 查看数据
对某一机器的所有优越感器序列做图:
1 | timeseries[timeseries['id'] ==20].plot(subplots=True, sharex=True, figsize=(10,10)) |
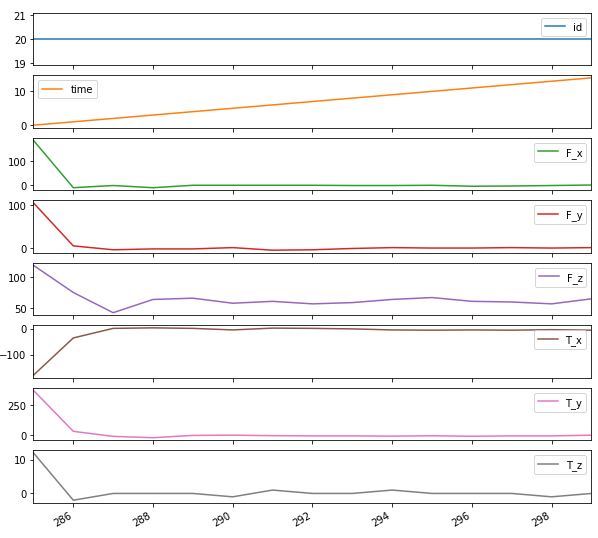
通过对比可以看到不同正常和异常的情况下,传感器波形的差异。
4.1.3 特征提取
1 | from tsfresh import extract_features |
可以看到针对 88 个不同 id 每成了 4000 多维特征。
一般情况下,输入和输出数据一般都为 dataframe 格式,column_id 用于指定时间序列所属的实体,本例中是不同机器;column_sort 用于标记时间顺序,某些功能可能仅适用于等距时间戳。如果不设置,则假定数据帧已按升序排序。
提取特征的具体定义请见:
Overview on extracted features
4.1.4 特征筛选
方法一
根据 y 筛选 X 特征(假设检验),并去掉空特征:
1 | from tsfresh import select_features |
清理后可以看到还剩 600 多维特征。
方法二
也可使用 calculate_relevance_table 函数做特征选择,用法如下:
1 | def calculate_relevance_table(X, y, ml_task='auto', n_jobs=1, show_warnings=False, chunksize=None, test_for_binary_target_binary_feature='fisher', test_for_binary_target_real_feature='mann', test_for_real_target_binary_feature='mann', test_for_real_target_real_feature='kendall', fdr_level=0.05, hypotheses_independent=False): |
它可以针对特征和目标变量的类型,设置具体的假设检验方法,返回数据为 pandas.DataFrame,主要包括特征、特征类型、假设检验 p 值、相关性等信息。
方法三
用以下命令将特征提取和特征选择合二为一:
1 | from tsfresh import extract_relevant_features |
tsfresh 可与 sklearn 连接使用,具体使用 sklearn 中的 pipeline 连接。
5 进阶
5.1 特征提取设置
上例中最终产生了 600 多维特征,当数据较多时,运行时间也比较长。tsfresh 提供了三种特征集:
settings.ComprehensiveFCParameters 全面参数
settings.EfficientFCParameters 有将参数
settings.MinimalFCParameters 最小参数
可以通过以下命令查看和编辑:
1 | from tsfresh.feature_extraction import settings |
提取特征时可通过 default_fc_parameters 或 kind_to_fc_parameters 来设置提取哪些特征,如:
1 | extracted_features = extract_features(timeseries, column_id="id", column_sort="time", default_fc_parameters=settings_minimal) |
参数 default_fc_parameters: 用于全局配置所需计算的特征;kind_to_fc_parameters 用于单独配置每一类数据所需计算的特征(推荐使用)。
default_fc_parameters 除了指定三种特征集,还可以使用字典指定具体参数,形如:
1 | fc_parameters = { |
kind_to_fc_parameters 也使用字典指定设置项,形如:
1 | kind_to_fc_parameters = { |
5.2 特征命名
提取的出特征都依据一定的命名规则(注意单下划线和多下划线,一般包括方法、参数等),可以从处理的数据中查看提取了哪些特征。
1 | settings.from_columns(extracted_features) |
另外,还可以针对不同的特征设置不同的提取项,以及设置具体的提取参数,请见源码中的例程:
1 | tsfresh/notebooks/examples/03%20Feature%20Extraction%20Settings.ipynb |
5.3 自定义特征提取
5.3.1 实现特征提取函数
如最简单的示例:加特征提取方法,用于计算众数:
1 | from tsfresh.feature_extraction import feature_calculators |
其中 simple 指的是简单方法:只返回单个值。
5.3.2 注册特征提取函数
方法一:
加入字典:tsfresh.feature_extraction.settings.ComprehensiveFCParameters
方法二:(推荐)
setattr(feature_calculators,name,func)
5.4 大量数据处理&并行计算
tsfresh 底层使用 numpy 而非 pandas,相对来说速度更快。但由于 numpy 不包含索引,因此丢弃了 dataframe 的索引信息,如需要使用或返回索引信息,则需要自行处理。
tsfresh 当数据量较很大时,对内存进行了优化(每次加载一些小块,其它存在磁盘上)。
tsfresh 底层也支持 dask(类似 pandas 的并行框架),但是默认使用。Dask 与 pandas 对比详见:Pandas模块替代品分析
tsfresh 默认开启了并行化,且支持分布式支持。
5.5 滑动时间窗口
待加
6 问题与解答
tsfresh 库 import 时很慢
把版本从 0.18 降成 0.17 之后就好了
7 一些想法
tsfresh 确实提取了几百维时序特征,但我们还是不知应该怎么使用,全部作为特征代入模型,让模型自行筛选?
8 参考
较长的综述
一个简单的例子
各种特征的原理
王半仙的 tsfresh 讲义