论文阅读_大模型情绪分析预测趋势
1 | 英文名称:Stock Price Trend Prediction using Emotion Analysis of Financial Headlines with Distilled LLM Model |
摘要
- 目标:探讨仅通过财务新闻标题中的情绪分析是否能够在无财务数据情况下预测股票价格趋势。
- 方法:使用轻量蒸馏大型语言模型分析财务新闻标题的情绪,再结合多种机器学习分类算法预测次日股价方向。
- 结论:基于新闻标题情绪的特征预测准确性可与使用传统财务数据的模型相当,不依赖抓取公司财务数据亦可有效预测股价走势。
读后感
内容简洁明了,各种具体的实现方法不仅清晰而且易于执行。惊喜的是,这里提到可以从 Kaggle 上下载 2009-2020 年间超过百万条的股票相关新闻数据(下载链接)。
不过这个预测的目标显得有些单一,仅仅是预测股价是涨是跌,相对而言较为简单。
1 引言
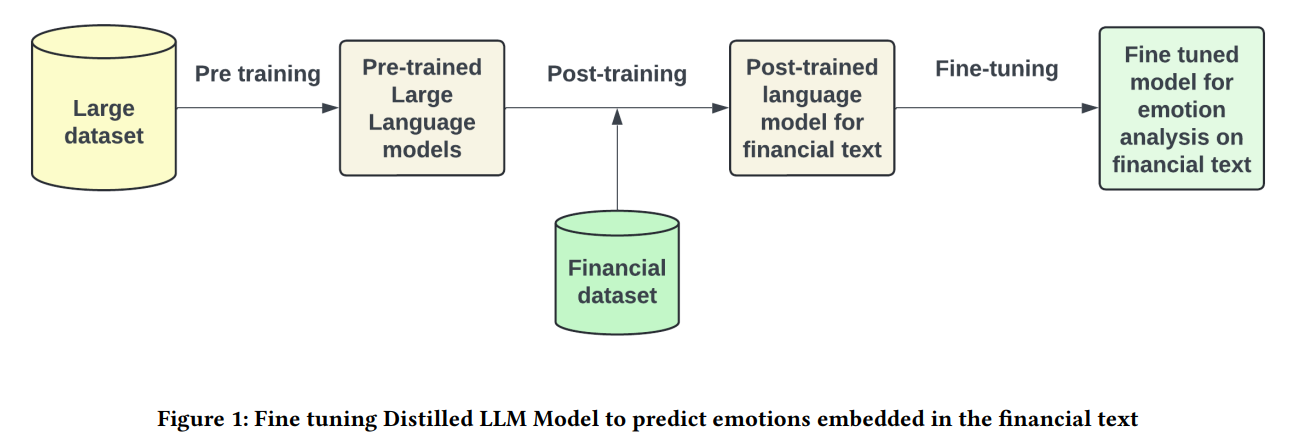
通过基于 API 的机制检索财经新闻头条,并训练轻量化、计算快速的蒸馏 LLM 模型,以捕捉公司金融新闻头条的情绪基调和强度。随后,我们将这些情绪信息与多种机器学习分类算法结合使用,仅通过新闻的情绪分析预测股价走势。我们证明,利用金融新闻标题中的情绪分析属性预测股价方向,与仅依赖财务数据运行的算法一样准确。
1.1 主要贡献
- 通过金融聚合器的 API 创建预测股票价格所需的数据集,避免了网络抓取用于策划金融数据集的复杂过程。
- 展示如何微调预训练的 LLM 模型,以有效预测财经新闻头条的情绪。
- 使用蒸馏的 LLM 模型执行文本分类任务,代替传统 NLP 方法,实现同样的目标。
- 针对情绪和财务特性,分别执行分类算法,以预测股价走势。
- 对所采用方法的局限性和挑战进行分析和讨论。
2 数据聚合
2.1 股票选择
本研究选取了来自美国的 32 家市值超过 2000 亿美元的大型上市公司。这些公司具有新闻曝光度高、数据丰富等特点,便于获取高质量的财经新闻,从而有效研究新闻标题所包含的信息与股价趋势之间的相关性。
收集了与这些公司相关的两个维度的数据:
- 财经新闻
- 股票的日常财务指标(开盘价、收盘价、成交量、当日最高价和最低价等)
2.2 财经新闻提取
为确保新闻数据的权威性与一致性,我们未采用网页爬虫,而是通过官方新闻聚合平台 NewsAPI.org 提取新闻内容。NewsAPI 提供免费和付费版本的服务,在免费计划下,每日可请求最多 100 条新闻数据,覆盖全球主流媒体。
需要注意的是,NewsAPI 的响应中并不包含完整的文章正文,仅提供新闻的标题、描述、来源、发布时间、图片链接及原文链接等元数据。
2.3 财务属性数据获取
股票价格及财务属性数据通过 Alpha Vantage 获取,该平台提供包括实时和历史数据在内的金融市场数据服务。用户需注册账号并获取 API Key。在免费额度下,每日最多请求 25 次数据,因此无法支持对所有公司进行高频监控。
获取的数据包括:
- 每日股价(开盘、收盘、最高、最低)
- 成交量
- 年度与季度收益报告等基本面信息
2.4 数据采集使用的工具库
我们分别使用 newsapi-python 和 alphavantage
两个官方 Python 包从上述 API
获取数据。这些库封装了常用请求方法,便于快速集成。
上述信息经清洗后统一存储至 Postgres 数据库。
2.5 历史新闻数据的补充
由于 NewsAPI 的免费套餐仅允许访问最近 30 天的数据,我们通过 Kaggle 补充了历史财经新闻数据,获取了 2009 年至 2020 年期间,涵盖 6,000 只股票的新闻标题数据,以提升模型的泛化能力与长期预测效果。
2.6 情绪分析
本研究引入情绪分析而非传统的情感(sentiment)分析,是为了获得更细致的情绪标签和更高维度的表达。相比二元(正面 / 负面)或三元(正面 / 中性 / 负面)情感分类,情绪分析提供了对具体情绪类别(如愤怒、喜悦、恐惧等)的识别,更有助于理解金融新闻中对市场潜在影响的细节。
2.7 模型选择策略
在本地部署了一款轻量级的蒸馏版语言模型:emotion-english-distilroberta-base。这是基于
RoBERTa-base 的变体,专为英文情绪识别任务优化。
该模型支持基于 Ekman 情绪理论的 7 类标签:
- 愤怒(anger)
- 厌恶(disgust)
- 恐惧(fear)
- 喜悦(joy)
- 悲伤(sadness)
- 惊讶(surprise)
- 中性(neutral)
该分类粒度适中,适合捕捉财经新闻标题中隐含的心理预期和市场反应倾向。
2.8 模型训练数据
为了增强模型对财经领域术语和表达的理解,我们采用有监督微调方法对模型进行定制训练。具体流程如下:
- 首先人工对一批财经新闻标题进行标注,每条标题分配一个情绪标签;
- 然后使用这些带标签的数据对基础模型进行训练,使其适应金融语境下的情绪识别任务。
训练的核心目标是提升模型对财经类文本的感知精度,而不仅仅依赖通用语料中的语言特征。
2.9 微调效果
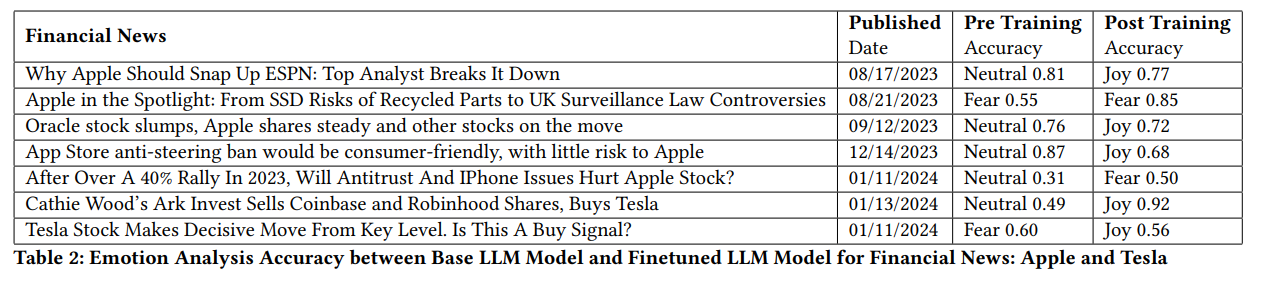
在微调阶段,我们仅使用了 76 条具有不同情绪标签的新闻标题进行训练,样本数量虽少,但模型表现有明显提升。微调后的模型在预测财经新闻的情绪类别上更加敏感,尤其对“恐惧”“惊讶”等高影响力情绪的识别更准确。
表 2 展示了模型微调前后的性能对比,具体指标包括准确率、召回率和 F1 分数,均有实质性改善。
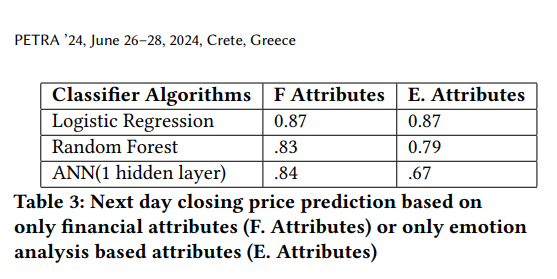
3 实验
- 实验一:通过 SQL 查询提取指定时间范围内的情绪标签、情绪强度(emotion_strength)以及收盘价。对 7 类情绪(愤怒、厌恶、恐惧、喜悦、中性、悲伤、惊讶)进行独热编码,转化为布尔特征。
- 实验二:提取同一时间段内的股价相关数据,包括开盘价、收盘价、最高价、最低价、成交量及收盘价的滚动平均。
- 为防止过拟合,两组实验均移除了公司名称、日期等非关键字段。
- 标签设置为二分类:若次日收盘价高于当日,则为 1,否则为 0。
- 数据按 8:2 比例划分为训练集和测试集。
- 两个实验均分别使用三种分类算法进行建模:逻辑回归、随机森林、人工神经网络(ANN)。