语言模型:文本表征&词嵌入技术调研
1 文本表征
文本表征是自然语言处理中的关键部分,尤其在当前大模型快速发展的背景下。由于大模型存在知识有限、处理文本长度有限、保密要求和大模型幻觉等问题,结合外部数据显得尤为重要。
为了便于存储和检索,除了保存纯文本外,还需要将文本转换为数组形式,以实现模糊查找和上下文语义理解。这使得在不同应用场景下如何进行编码成为一个重要课题。
我最近在优化本地知识存储,调研了一些文本表征方法,包括:文本表征发展过程、相关中文资源、检索增强生成的优化方法、词向量与早期文本数据库工具结合,以及在信息提取、社交网络和电子商务领域中词嵌入的优化方法。共八个部分,将在之后的 8 天内在公众号连载。本文作为开篇,先给出收获和总结。(下文中 Embedding 与嵌入同义)
关键字:embedding-based retrieval,RAG,Information Retrieval
2 问题与解答
在调研之前,我一直有以下一些疑问。在研读过程中,我得到了答案和启发。以下是我目前的个人理解,可能并不完全正确。
2.1 问题一
本地知识库是否必须使用深度学习表示?
目前,知识表示的主要方法包括:基于规则的方法、统计方法和基于神经网络的方法。
现在常说的 Embedding 一般指的是基于深度学习神经网络的稠密向量存储。它对文本理解的效果是目前最好的,但在存储、转换和索引过程中占用的资源和复杂度也更大。
是否需要使用 Embedding 主要取决于使用场景。如果多数情况下只做关键字搜索和模糊搜索,使用基于规则或者统计的方法即可,无需 Embedding。但是,如果想基于本地知识做问答系统,涉及较多文本理解和对话上下文,则需要 Embedding。
其核心逻辑是:Embedding 可以理解字面意思以外的深层意思。
2.2 问题二
除了知识库,文本表示的主要应用场景有哪些?
可以说,有文字并且需要整理、预测或决策的地方都能用到文本表示。
从几篇关于 Embedding 应用的较新论文可以看出,在电子商务、信息提取、社会网络中,匹配、分类和聚类这些场景都用到了 Embedding。
在电子商务领域可将技术转换成经济利益,该领域也最先尝试了各种先进技术。例如,京东和 Facebook Marketplace 分别对 Embedding 做了扩展。在用户层面上利用搜索关键字及用户特征进行编码;在商品层面上,对商品描述文本、商品特征和图片等进行编码。然后,将用户和商品编码映射到同一空间,以实现匹配。这种编码也可视为一种多模态复杂嵌入,是嵌入的广义解释。
在不同的专业领域,扩展和精调是嵌入的常用优化方法。而通用表示则可以不依赖具体数据集,就能像人一样理解文本的含义。编码后,可以进行进一步的分类、聚类以及预测。几乎所有涉及文字预测的场景都可以使用通用嵌入。
在信息提取时,对于特定领域(如识别病虫害),从各种格式和风格的文本中提取信息。之前需要使用规则、命名实体识别,关系识别,主题建模……涉及非常复杂的步骤和模型设计与训练。现在,通过大模型对文本解析,大部分功能可直接实现。从以人为主导变成以数据为主导,人只需做简单干预和审查。而嵌入在其中充当了特征提取和过程存储的重要角色。
在知识发现和特征挖掘方面,Embedding 可能起到很大的作用。
2.3 问题三
向量存储适用于哪些场景?如何选模型?
需要考虑具体的场景、响应速度要求以及成本预算。下面列出三种常见场景:
如果是个人知识库或者狭小领域的知识构建,比如我自己的知识库,内容基本都是手动撰写输入的,体量在百万字级别。无论是自己搭建的嵌入环境还是调用网络 API 工具,成本都不算高,因此不需要太多优化。如果是多人使用的知识库,可以先分用户,然后再检索,向量的计算量也并不大,可以考虑使用 pgvector 级别的解决方案。
如果是一个公司内部知识库,有相对较多的文档,可以考虑用 Lucene 或者 ElasticSearch 对向量扩展支持,自己选型和搭建 Embedding 本地服务。
如果是更大的商用场景,比如做商城,有很多商品和用户,多对多的检索场景,不仅需要做向量库向量检索,还需要针对 Embedding 模型进行优化。
对于 Embedding 模型选型,如果只是对一个简单领域做实验,那么可以选择一种排行榜前列中文的 Embedding 模型,或者调用 OpenAI 的 embedding API 即可。如果数据很多,而且是特定领域的数据,比如医学领域数据,则可以找相关领域的成熟模型,或者用自己的数据进行精调。
2.4 问题四
5000 个字和 5 个字的 embedding 可比吗?
这种问题通常出现在检索的场景中:搜索与关键字最匹配的文档。
在向量匹配过程中,最常用的算法是点积或者计算余弦距离。余弦距离可以看作是点积的归一化结果。点积简单来说就是将向量每个维度的值相乘然后相加。
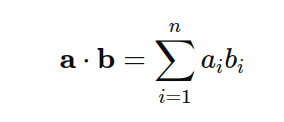
对于离散稀疏的向量,比如 A:[1,1,1,1,0] 与 B:[0.1,0,0,0],相关于计算 A 和 B 的交集,点积结果是 [0.1, 0, 0, 0]。稠密向量也类似,当各维度值大且方向一致时,得分高。在查询场景下,对于 N 个文档,与关键词与文档交集越大分数越高。最佳匹配得分本身不一定很高,只要比其他文档高就得到了优先权。
同样由于没有一个绝对距离,无法确定阈值。虽然可以得到命中率的排序,但如果这个关键词与哪个文档相关度都不高,则会返回完全不相关的结果,显得很不靠谱。可以说 Embedding 能实现模糊搜索,但更擅长生成文本。
在有些场景下,统计方法也优于嵌入方法。例如 TF/IDF 利用词频能够定位到文档中一些关键性的词或短语。而使用嵌入方法做文档比较和检索,则更侧重文本本身的相似程度,而不是更有特点的内容。因此,目前很多优化方法使用多种检索方式结合起来。
2.5 问题五
在搜索场景下,embedding 需要考虑上下文吗?
这是一个与交互设计相关的问题。通常情况下,搜索是用户在一个框中输入关键字,这种情况下一般不涉及上下文。当然,也可以将当前文档或者之前的搜索作为背景上下文,但可能提升不多。
在一些特定的搜索场景中,比如商品搜索,用户的个人资料和之前的操作、购买记录都可以作为上下文,与关键字一起生成嵌入,用于匹配商品嵌入,这可能比较有价值。
另外,在社交场景或对话交互中的检索,例如用户想找 " 张三 ",可以将之前的对话、当前用户的社交网络和地域作为选择目标张三的上下文;近期事件和热点事件也应该有更高的命中率,而这些特征各自的权重参数可以通过学习训练获得,不但需要考虑上下文,还涉及进一步的优化 Embedding 方法。
2.6 问题六
大语言模型 LLM 与 Embedding 是什么关系
目前的嵌入技术与 LLM 的底层技术(如:GPT, BERT)和优化方法(如:多模态、多语言、整合知识图、领域定制)基本相同。理论上,可以用 LLM 的一些上层输出作为嵌入。不过,它们的侧重点有所不同。本地部署 7G-70G 左右的 LLM 模型是主流方法,而我们常常选用 1G 以内的模型作为嵌入模型。
总之,二者之间的技术基本是通用的,而侧重点不同。LLM 尽量融入更多知识,以适合复杂应用场景,对推理和数学等全科水平都有期待;而嵌入则相对简单,更侧重语文能力。可以说,嵌入是 LLM 的能力子集。
2.7 总结
很多程序员很喜欢拥抱新技术。有很多技术,一开始觉得还真不错,但装上之后,并不经常用。还带来了一定的资源占用。尝试固然是好的,但在工程领域,请不要为了使用新技术而使用新技术。请以问题为导向,尽量找到痛点,解决问题。
如非必要,勿增实体
请遵循“奥卡姆剃刀”(Occam's Razor)原理,如非必要,勿增实体。根据需要选择:关键字 -> 统计 -> 深度学习。在当前已有稳定系统的情况下,如果没有特定的需求,不要大改,因为效果,稳定性,支出各个方面都不一定好。
比如我在优化本地知识库 Obsidian 时,先后尝试过基本于统计的搜索 OmniSearch,本地插件文本嵌入 Smart connection,以及可部分在服务端的 khoj 做进一步的知识管理。一开始原的时候觉得功能很好。但在日常使用时,使用场景非常少,而因为它需要做各种索引,还让系统变慢,让使用体验变差了。
这个方向的新技术确实对应更高的成本,而且可以考虑多模式并存的方式,
对话与检索,稀疏与稠密
在检索中不一定非要使用深度学习方法,深度学习方法相对于统计方法,可以参考上下文语义理解关键字,并且可以生成通用的语义。而如果只检索需要关键字,也没有什么上下文。
RAG 检索增强生成,它初始的目标是更好的生成,而不是简单的检索。也可以说,其主要的应用领域是生成而非检索。所以,方法的选择取决于具体应用和预算,不一定非要使用新方法。
稀疏与稠密向量的存储、匹配和索引方法各不相同,用于存储不同方法产出的结果。它们还可以相互转化,例如,通过特征筛选或特征映射将稀疏向量变为稠密向量。未来,也可能会出现像 LORA 这样的方法,将稠密向量进一步压缩。
通用模型与特定任务模型
通用文本嵌入比特定于任务的文本嵌入更具挑战性。目前的评测工具,不论是中文还是英文,都可对语义相似度、分类、聚类、检索、重排等多种能力打分。可以参考 huggingface 嵌入排行榜选型。
目前,也有一些开放的训练数据,可以参考这些数据,加入自己的数据,在基模上微调。不过请注意,本地数据可能会导致模型偏差。微调后,可以使用工具(如 C-PACK)评测微调后的模型在旧任务上的得分,而不是随意想几个问题自己测试。